I’m interested in creating an NMT model that is capable of translating text very quickly on a GPU. For my application, sacrificing BLEU (quality) is acceptable, but I would like to be able to translate 10-100 times more quickly than the translation speed of the default models (or better).
On my hardware - a GeForce GTX 1080 - I can get 340 tokens/sec for translation speed out-of-the-box (i.e. not setting any parameters in onmt).
I am considering sweeping through the parameter space for training (http://opennmt.net/OpenNMT/options/train/), but it would be nice to get some expert opinions on which parameters we ought to expect to matter.
That seems already like a lot to me. Do you mean 250 tokens/sec?
Without retraining your model, you can set -beam_size 1 during translation to decode with greedy search.
Otherwise, every options that control the model size impact the performance: -word_vec_size, -rnn_size, -layers, etc. The lower the values, the faster the translation. However, at some point you’ll get very bad translations.
Ah, you are correct, I made an error in my analysis code, I was counting chars instead of tokens. I will correct my OP.
OK, the true figure is ~300 tokens/sec fully vanilla and out of the box.
every options that control the model size impact the performance: -word_vec_size, -rnn_size, -layers, etc. The lower the values, the faster the translation.
Do you know whether there is any existing research on what the tradeoffs in the space look like?
In particular, I expect that at some point reducing parameters would provide no further benefit due to vectorization of operations on the GPU, but I’m not familiar enough with OMNT to know when that will start to happen.
If not, I might start some experiments and post the results here to benefit others.
Thanks, that sounds pretty interesting. From skimming the sequence-level knowledge distillation paper, it seems that one could just train a small model on the output of a big model and get some benefit?
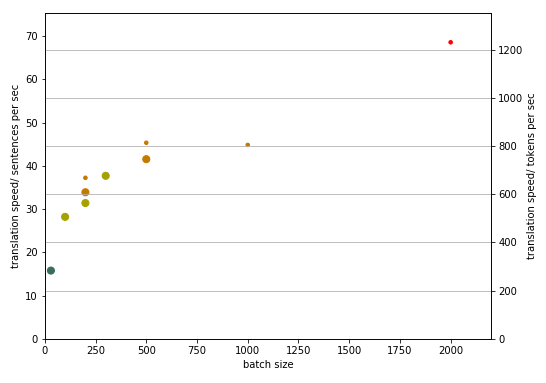
I performed some experiments to test how BLEU varies with network size. For 800,000 sentences in two European languages, I found that I got 45.5 BLEU with a network size and embedding dimension of 125, which only increased to 49.5 with a network size and embedding dimension of 500.
I have not had time to try the trick proposed in Kim et al suggested by @jean.senellart .
In terms of translation speed, models with network size and dimension 125 do not seem to utilize the GPU resources very well, nvidia-smi shows very sporadic GPU usage, though speed does seem to scale with batch size. However, at some point the GPU runs out of memory and crashes as the batch size is increased beyond ~3000.
Perhaps I need to run multiple instances of the translate.lua process on the same GPU to get around this inefficiency?
beyond about 600 tokens/sec and a batch size of 250 I get a change in scaling behavior. I will attempt multiple processes and see whether it helps.
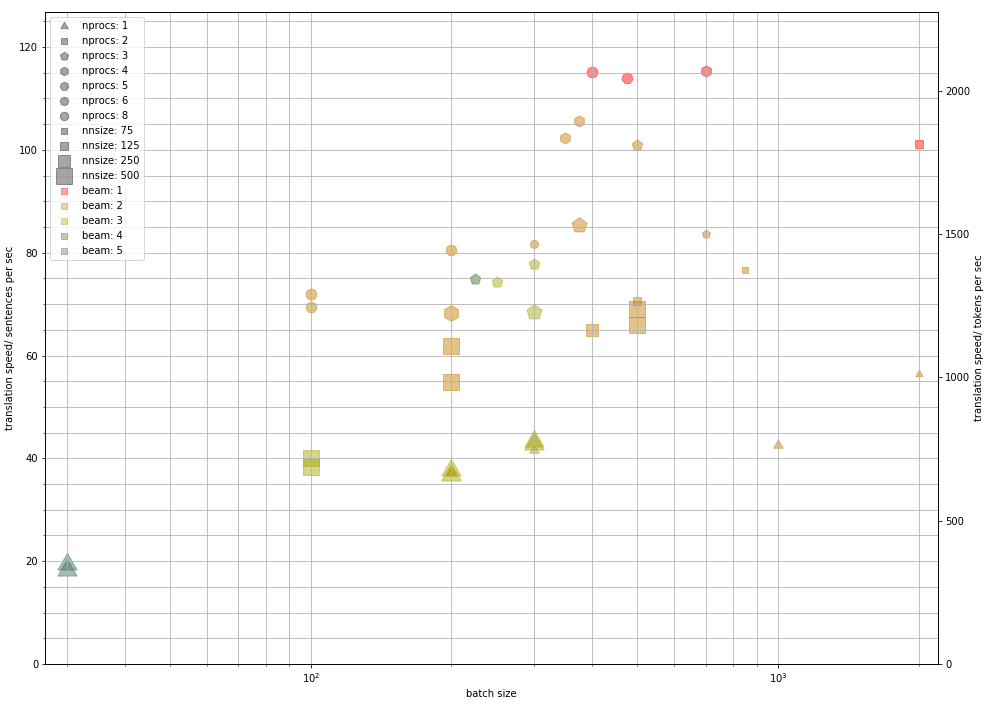
After further investigation, it seems that one can get more performance out by using multi-processing to submit multiple jobs to the GPU simultaneously, at least when dealing with a small model.
The number of jobs must be balanced against the batch size and model size. If you go over the graphics memory, oNMT will crash.
I was able to attain 1750 tokens/sec in this manner.
Further experimentation allowed me to achieve up to 2068 tokens/second.
It seems that the best way to make full use of the GPU’s resources to max out translation speed is to:
use a model with a network size of approx. 125. Larger Models up to 200 may also be optimal, but by 250 you are taking a speed penalty. Smaller models do not seem to help, so don’t bother.
use 3-5 processes, where each process has an equal fraction of the data your are translating, and launch them in parallel, all pointing at the same GPU.
use a batch size such that your GPU memory is mostly used up. In the case of my GTX 1080 with 8GB of graphics memory, that turns out to be about 300-400 for models of size 125.
reduce the beam width to 2. There is little benefit in going to a beam of 1, for some reason.
Together these optimizations will give you a speedup from ~350 tokens/sec/GPU to ~2000 tokens/sec /GPU on a comparable piece of hardware.
I’ll post any updates about performance and BLEU if I can.