Hi,
I’m tring to transformer for translation with opennmt-py.
And I already have the tokenizer trained by sentencepiece(unigram).
But I don’t know how to use my custom tokenizer in training config yaml
I’m refering the site of opennmt-docs (https://opennmt.net/OpenNMT-py/examples/Translation.html)
Here are my code and the error
# original_ko_en.yaml
## Where is the vocab(s)
src_vocab: /workspace/tokenizer/t_50k.vocab
tgt_vocab: /workspace/tokenizer/t_50k.vocab
# Corpus opts:
data:
corpus_1:
path_src: /storage/genericdata_basemodel/train.ko
path_tgt: /storage/genericdata_basemodel/train.en
transforms: [sentencepiece]
weight: 1
valid:
path_src: /storage/genericdata_basemodel/valid.ko
path_tgt: /storage/genericdata_basemodel/valid.en
transforms: [sentencepiece]
#### Subword
src_subword_model: /workspace/tokenizer/t_50k.model
tgt_subword_model: /workspace/tokenizer/t_50k.model
src_subword_nbest: 1
src_subword_alpha: 0.0
tgt_subword_nbest: 1
tgt_subword_alpha: 0.0
# filter
# src_seq_length: 200
# tgt_seq_length: 200
# silently ignore empty lines in the data
skip_empty_level: silent
# Train on a single GPU
world_size: 1
gpu_ranks: [0]
# General opts
save_model: /storage/models/opennmt_v1/opennmt
keep_checkpoint: 100
save_checkpoint_steps: 10000
average_decay: 0.0005
seed: 1234
train_steps: 500000
valid_steps: 20000
warmup_steps: 8000
report_every: 1000
# Model
decoder_type: transformer
encoder_type: transformer
layers: 6
heads: 8
word_vec_size: 512
rnn_size: 512
transformer_ff: 2048
dropout: 0.1
label_smoothing: 0.1
# Optimization
optim: adam
adam_beta1: 0.9
adam_beta2: 0.998
decay_method: noam
learning_rate: 2.0
max_grad_norm: 0.0
normalization: tokens
param_init: 0.0
param_init_glorot: 'true'
position_encoding: 'true'
# Batching
batch_size: 4096
batch_type: tokens
accum_count: 8
max_generator_batches: 2
# Visualization
tensorboard: True
tensorboard_log_dir: /workspace/runs/onmt1
and When I typing < onmt_train -config xxx.yaml >
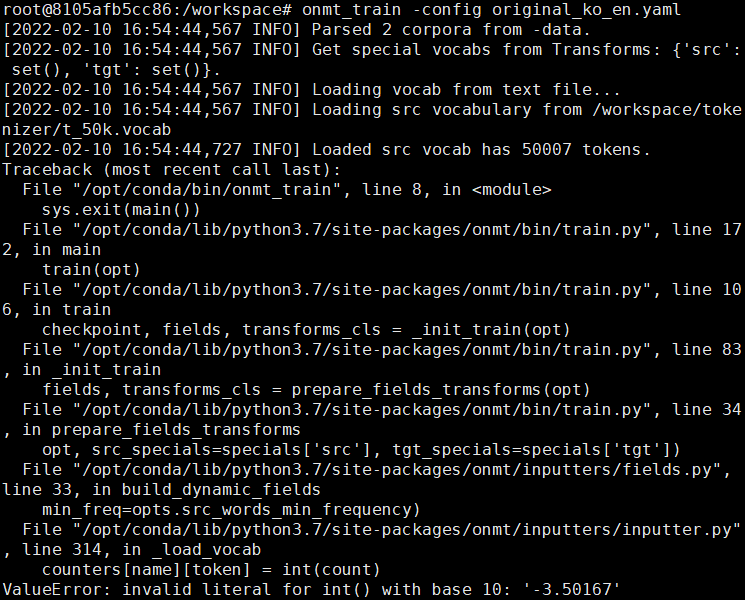
So, the questions are two.
- my sentencepiece tokenizer embedding is float. How can i resolve the int error?
- When training stopped by accident or I want to train more some model.pt
what is the command to start training from the some model.pt ?
I’ll look forward to any opinion.
Thanks.