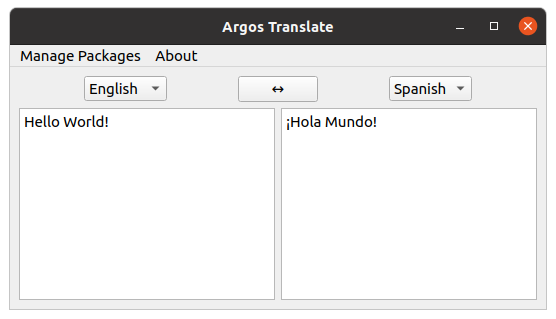
I’ve been working on a GUI and package system built on OpenNMT models to make it easier to do translation locally. It’s designed to be used either as a GUI application or as a Python library and can be installed from PyPI or the Snap Store for Linux. I’ve also trained and packaged models for a number of languages (you can also download just the checkpoints if you want to use them without my app).
The packages contain a quantized CTranslate model, files for tokenizing with SentencePiece, and files for doing sentence boundary detection with Stanza. Big thanks to @BramVanroy for recommending using Stanza for sentence boundary detection. I wanted to do sentence boundary detection in a way that would support a variety of languages and was really struggling to find something.
The GUI lets you install packages and do translation all from a GUI and is built on PyQt which makes it reasonably cross platform. I also do the necessary threading and some caching to make this a decent user experience.
Currently I have models to translate to and from English with Arabic, Chinese, French, Russian, and Spanish. I also have a script with (light) documentation that makes it easy to get up and training models quickly and package them. The models seem to generally perform well although I couldn’t find as much data for Chinese and it’s not as good as the others.
I’m not totally sure I don’t know what SavedModels are, maybe someone more familiar with OpenNMT can answer. The code I used for training and exporting is available if you want to look at it. Unfortunately, I seem to have accidentally deleted the Docker container that I was training the models in and don’t have the data to re-export (though very fortunate that this happened right after not before exporting). My understanding though is that all the information you would need is in the checkpoint. What I uploaded is just the raw OpenNMT checkpoints + tokenizing information all I did was average the checkpoints.
SavedModels are an exported format that is introduced by Tensorflow
The advantage is that Argos translate can be used by a larger audience, tensorflow and OpenNMT.
Another advantage is that it is independent from the translation engine, so the translation quality shouldn’t change, but I can’t say for sure.
Here is a link how to run it: https://github.com/OpenNMT/OpenNMT-tf/tree/master/examples/serving
From what I can tell the pretrained English-German model that’s linked on the OpenNMT website is distributed as both a checkpoint and a SavedModel. My project is based on CTranslate models generated from OpenNMT averaged checkpoints so that’s what I’ve focused on. I don’t know if SavedModels can be generated from checkpoints + tokenizing information but maybe that would be useful to some people.
I think using CTranslate2 is the correct choice for this type of offline application. It should be much more efficient and flexible than TensorFlow’s SavedModel, especially in memory usage (on disk and at runtime).
While browsing the code, I see that you are running translation on a single sentence at a time:
Instead you should prefer doing batch translation for better performance. Basically you can pass all tokenized sentences to translate_batch and set max_batch_size to limit memory usage, e.g.:
translator.translate_batch(
[sp_processor.encode(sentence, out_type=str) for sentence in sentences],
max_batch_size=32)
Ctranslate2 is super fast and lightweight but it has a big disadvantage; the model is dependent on the engine, a new release effects translation, and the translation is different from the checkpoint.
In my case quality of translation is way much more important than speed, also the speed factor is not as important with offline applications.
Of course if speed or efficiency is not a concern, then there is no point in integrating CTranslate2. But for offline applications, efficiency seems very important otherwise some users with few memory and CPU resources will not be able to use your application.
Note that running a checkpoint with a different TensorFlow version or on a different hardware can also change the model output.