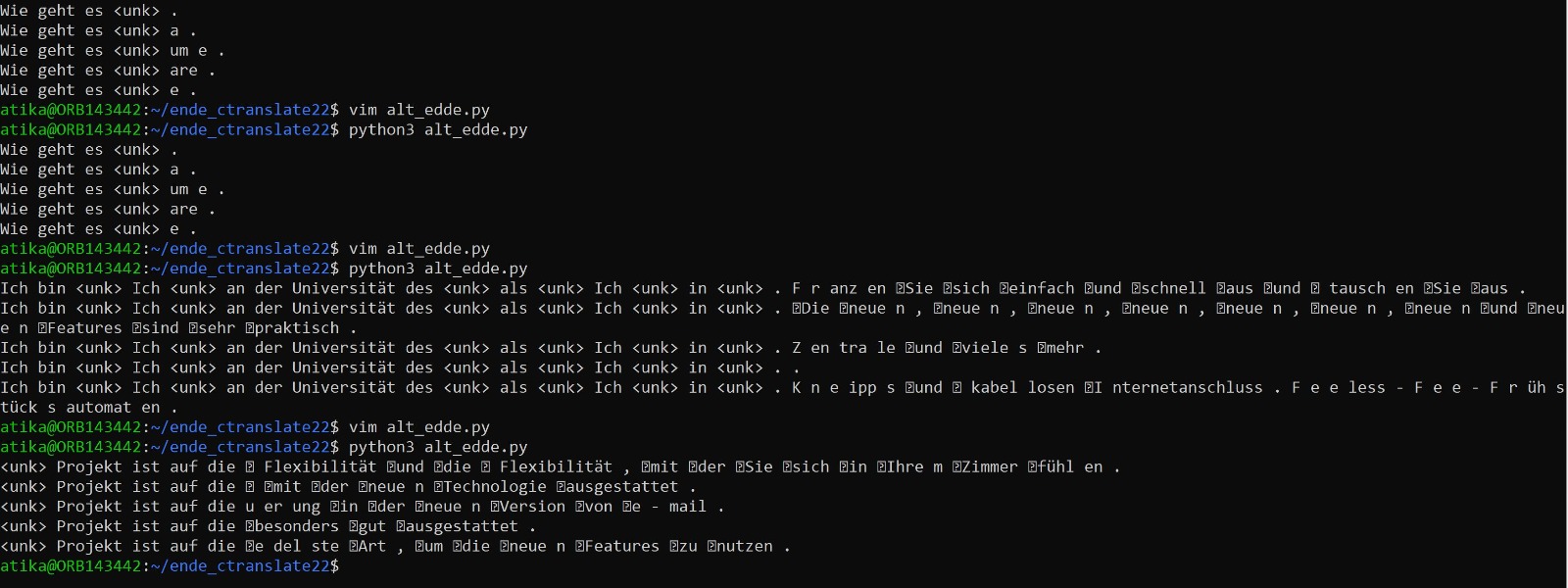
I am trying to run ‘Alternative at position’ the decoding feature of Ctranslate2 but getting in the translated alternative sentences. Could you please tell me where i am doing mistake and how I can resolve this issue.
Script
import ctranslate2
translator = ctranslate2.Translator("ende_ctranslate2/")
Input = "This project is geared towards efficient serving of standard translation models but is also a place for experimentation around model compression and inference acceleration."
def tokenize(data):
return data.split(" ")
def detokenize(data):
return " ".join(data)
results = translator.translate_batch(
[tokenize(Input)],
target_prefix=[tokenize("Dieses Prokekt ist auf die")],
num_hypotheses=5,
return_alternatives=True)
for hypothesis in results[0]:
print(detokenize(hypothesis["tokens"]))
Output after run about script
I tried with different input english sentences and getting this result.
I am sorry but I did not clearly understand what you are trying to say.
I download the wmt-ende-sp data and get two files ‘wmtende.model’ and ‘wmtende.vocab’ files. So should I include this two files in my above mentioned script?
Also, I have a look on the page that you shared, but unfortunately i did not get as much. I feel the instruction that is mentioned on the page is create .model and .vocab file but I already have these two files and i need to run.
Could please explain more what exactly i have to do for ‘alternative at position’. I am really sorry to bother you because I am very new user and dont have good understanding about these.