I’m interested in finetuning a general domain model with a specific domain. I’ve previously finetuned some models using OpenNMT-py’s previous version. However, I can’t find any information for the newest version. Can anyone give me some keys?
The underlying model and training structure did not change in 2.0, just the data loading process. You can check how the config files work in the updated docs, and just use train_from to start from your model, and src_vocab to keep the same vocab.
If facing specific issues or questions, you might want to be more precise.
The case is not explicitly handled (yet) in OpenNMT-py.
Technically you could ‘update’ the vocabulary of an existing model and finetune from there. You would indeed need to initialize some parameters of the model for the new tokens.
It would be nice to add this as a standalone script. Let us know if you would like to contribute and need pointers to get started.
To train a model, you need a vocab. Because parameters of the network are tied to a specific input/output index corresponding to a word/token. So, an existing model has a fixed vocab, in the sense that it expects a range of indices in input, and produces a range of indices in output.
You can technically pass a new vocab when using train_from. But your vocab will probably not be the same size and produce an error. And, if the vocab is the same size, the indices will probably not match so the model won’t train properly. (E.g. the index for “banana” would now be the index for “beach”, and your model would have to learn everything again.)
Note that build_vocab is merely a helper tool to prepare a vocab (basically a list of words/tokens), but the vocab passed to train could be built by any other tool as long as it’s in the proper format.
Thanks. That was really clarifying, I suspected it would be so but I wanted to be sure.
When finetuning on a new domain my approach is to use weighted corpora in training and a mix of in domain and out domain corpora for evaluation:
Training data: out of domain (60%) and in domain (40%)
Evaluation data: out of domain (50%) and in domain (50%)
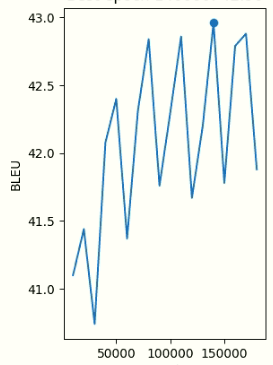
During the training process, BLEU keeps improving on the evaluation set:
Just to see what’s going on with the test, I periodically test the model on in domain data. What I noticed is that it seems to have in domain kwonledge until some point in the training which improves the baseline. However, from that point, even if the model improves BLEU on development data the model starts performing worse on in domain test. Any clues why I get this behaviour? Is it because I have out of domain data in the evaluation set? It happens with different percentages of weighted training data…
Ok so there is no shuffling issue.
I don’t really know what might be happening here. Maybe your in-domain test set is not representative of your in-domain train data (or the opposite). Did you try weighting your in-domain dataset even more (like out-domain 1 and in-domain 10)?
You mentioned it would be nice to add new tokens in vocabulary as a standalone script. Do you mena something similar to build_vocab.py? Apply transforms to the new corpus and update src and tgt counters and the crresponding vocabulary files?
I’m interested in implementing this feature.
EDIT: I’ve edited with minimal changes build_vocab.py to accept a new argument --update_vocab to update existing vocabulary files with new corpora. I still need to edit the training scripts.