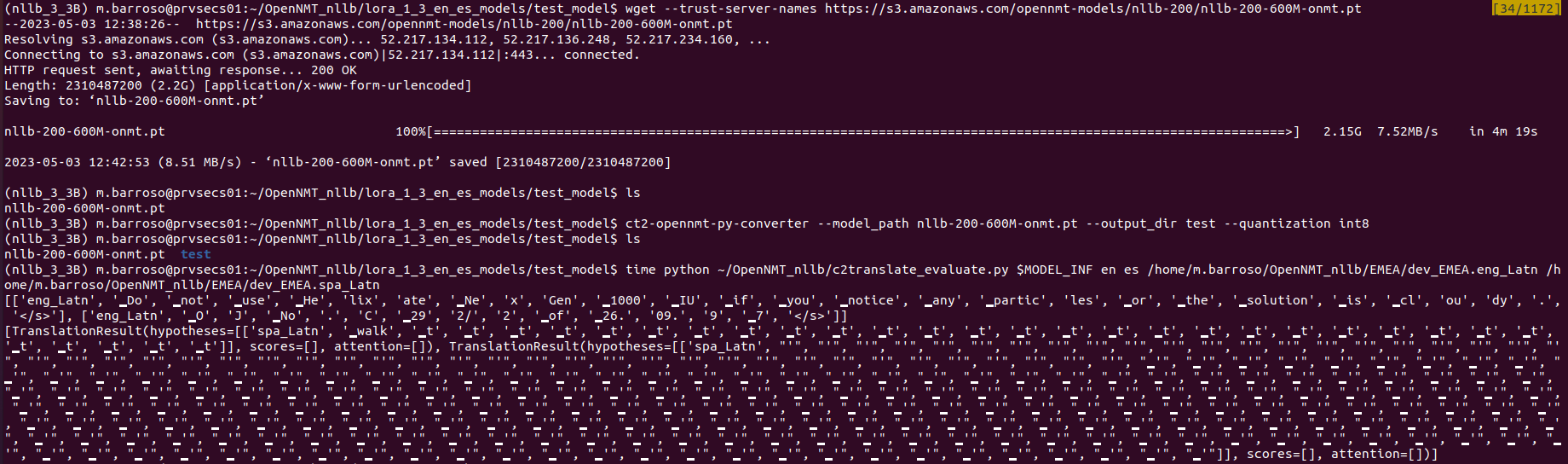
After doing this, I get the following error when I run inference with the new nllb-finetuned.pt:
Traceback (most recent call last):
File "/home/m.barroso/anaconda3/envs/nllb_3_3B/bin/onmt_translate", line 33, in <module>
sys.exit(load_entry_point('OpenNMT-py', 'console_scripts', 'onmt_translate')())
File "/home/m.barroso/OpenNMT_nllb/OpenNMT-py/onmt/bin/translate.py", line 60, in main
translate(opt)
File "/home/m.barroso/OpenNMT_nllb/OpenNMT-py/onmt/bin/translate.py", line 23, in translate
translator = build_translator(opt, logger=logger,
File "/home/m.barroso/OpenNMT_nllb/OpenNMT-py/onmt/translate/translator.py", line 33, in build_translator
vocabs, model, model_opt = load_test_model(opt)
File "/home/m.barroso/OpenNMT_nllb/OpenNMT-py/onmt/model_builder.py", line 171, in load_test_model
model = build_base_model(model_opt, vocabs, checkpoint)
File "/home/m.barroso/OpenNMT_nllb/OpenNMT-py/onmt/model_builder.py", line 402, in build_base_model
model.load_state_dict(checkpoint['model'],
File "/home/m.barroso/anaconda3/envs/nllb_3_3B/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1671, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for NMTModel:
Missing key(s) in state_dict: "encoder.transformer.0.self_attn.linear_keys.bias", "encoder.transformer.0.self_attn.linear_values.bias", "encoder.transformer.0.self_attn.linear_query.bias", "encoder.transformer.0.self_attn.final_linear.bias", "encoder.transformer.1.self_attn.linear_keys.bias", "encoder.transformer.1.self_attn.linear_values.bias", "encoder.transformer.1.self_attn.linear_query.bias", "encoder.transformer.1.self_attn.final_linear.bias", "encoder.transformer.2.self_attn.linear_keys.bias", "encoder.transformer.2.self_attn.linear_values.bias", "encoder.transformer.2.self_attn.linear_query.bias", "encoder.transformer.2.self_attn.final_linear.bias", "encoder.transformer.3.self_attn.linear_keys.bias", "encoder.transformer.3.self_attn.linear_values.bias", "encoder.transformer.3.self_attn.linear_query.bias", "encoder.transformer.3.self_attn.final_linear.bias", "encoder.transformer.4.self_attn.linear_keys.bias", "encoder.transformer.4.self_attn.linear_values.bias", "encoder.transformer.4.self_attn.linear_query.bias", "encoder.transformer.4.self_attn.final_linear.bias", "encoder.transformer.5.self_attn.linear_keys.bias", "encoder.transformer.5.self_attn.linear_values.bias", "encoder.transformer.5.self_attn.linear_query.bias", "encoder.transformer.5.self_attn.final_linear.bias", "encoder.transformer.6.self_attn.linear_keys.bias", "encoder.transformer.6.self_attn.linear_values.bias", "encoder.transformer.6.self_attn.linear_query.bias", "encoder.transformer.6.self_attn.final_linear.bias", "encoder.transformer.7.self_attn.linear_keys.bias", "encoder.transformer.7.self_attn.linear_values.bias", "encoder.transformer.7.self_attn.linear_query.bias", "encoder.transformer.7.self_attn.final_linear.bias", "encoder.transformer.8.self_attn.linear_keys.bias", "encoder.transformer.8.self_attn.linear_values.bias", "encoder.transformer.8.self_attn.linear_query.bias", "encoder.transformer.8.self_attn.final_linear.bias", "encoder.transformer.9.self_attn.linear_keys.bias", "encoder.transformer.9.self_attn.linear_values.bias", "encoder.transformer.9.self_attn.linear_query.bias", "encoder.transformer.9.self_attn.final_linear.bias", "encoder.transformer.10.self_attn.linear_keys.bias", "encoder.transformer.10.self_attn.linear_values.bias", "encoder.transformer.10.self_attn.linear_query.bias", "encoder.transformer.10.self_attn.final_linear.bias", "encoder.transformer.11.self_attn.linear_keys.bias", "encoder.transformer.11.self_attn.linear_values.bias", "encoder.transformer.11.self_attn.linear_query.bias", "encoder.transformer.11.self_attn.final_linear.bias", "encoder.transformer.12.self_attn.linear_keys.bias", "encoder.transformer.12.self_attn.linear_values.bias", "encoder.transformer.12.self_attn.linear_query.bias", "encoder.transformer.12.self_attn.final_linear.bias", "encoder.transformer.13.self_attn.linear_keys.bias", "encoder.transformer.13.self_attn.linear_values.bias", "encoder.transformer.13.self_attn.linear_query.bias", "encoder.transformer.13.self_attn.final_linear.bias", "encoder.transformer.14.self_attn.linear_keys.bias", "encoder.transformer.14.self_attn.linear_values.bias", "encoder.transformer.14.self_attn.linear_query.bias", "encoder.transformer.14.self_attn.final_linear.bias", "encoder.transformer.15.self_attn.linear_keys.bias", "encoder.transformer.15.self_attn.linear_values.bias", "encoder.transformer.15.self_attn.linear_query.bias", "encoder.transformer.15.self_attn.final_linear.bias", "encoder.transformer.16.self_attn.linear_keys.bias", "encoder.transformer.16.self_attn.linear_values.bias", "encoder.transformer.16.self_attn.linear_query.bias", "encoder.transformer.16.self_attn.final_linear.bias", "encoder.transformer.17.self_attn.linear_keys.bias", "encoder.transformer.17.self_attn.linear_values.bias", "encoder.transformer.17.self_attn.linear_query.bias", "encoder.transformer.17.self_attn.final_linear.bias", "encoder.transformer.18.self_attn.linear_keys.bias", "encoder.transformer.18.self_attn.linear_values.bias", "encoder.transformer.18.self_attn.linear_query.bias", "encoder.transformer.18.self_attn.final_linear.bias", "encoder.transformer.19.self_attn.linear_keys.bias", "encoder.transformer.19.self_attn.linear_values.bias", "encoder.transformer.19.self_attn.linear_query.bias", "encoder.transformer.19.self_attn.final_linear.bias", "encoder.transformer.20.self_attn.linear_keys.bias", "encoder.transformer.20.self_attn.linear_values.bias", "encoder.transformer.20.self_attn.linear_query.bias", "encoder.transformer.20.self_attn.final_linear.bias", "encoder.transformer.21.self_attn.linear_keys.bias", "encoder.transformer.21.self_attn.linear_values.bias", "encoder.transformer.21.self_attn.linear_query.bias", "encoder.transformer.21.self_attn.final_linear.bias", "encoder.transformer.22.self_attn.linear_keys.bias", "encoder.transformer.22.self_attn.linear_values.bias", "encoder.transformer.22.self_attn.linear_query.bias", "encoder.transformer.22.self_attn.final_linear.bias", "encoder.transformer.23.self_attn.linear_keys.bias", "encoder.transformer.23.self_attn.linear_values.bias", "encoder.transformer.23.self_attn.linear_query.bias", "encoder.transformer.23.self_attn.final_linear.bias", "decoder.transformer_layers.0.self_attn.linear_keys.bias", "decoder.transformer_layers.0.self_attn.linear_values.bias", "decoder.transformer_layers.0.self_attn.linear_query.bias", "decoder.transformer_layers.0.self_attn.final_linear.bias", "decoder.transformer_layers.0.context_attn.linear_keys.bias", "decoder.transformer_layers.0.context_attn.linear_values.bias", "decoder.transformer_layers.0.context_attn.linear_query.bias", "decoder.transformer_layers.0.context_attn.final_linear.bias", "decoder.transformer_layers.1.self_attn.linear_keys.bias", "decoder.transformer_layers.1.self_attn.linear_values.bias", "decoder.transformer_layers.1.self_attn.linear_query.bias", "decoder.transformer_layers.1.self_attn.final_linear.bias", "decoder.transformer_layers.1.context_attn.linear_keys.bias", "decoder.transformer_layers.1.context_attn.linear_values.bias", "decoder.transformer_layers.1.context_attn.linear_query.bias", "decoder.transformer_layers.1.context_attn.final_linear.bias", "decoder.transformer_layers.2.self_attn.linear_keys.bias", "decoder.transformer_layers.2.self_attn.linear_values.bias", "decoder.transformer_layers.2.self_attn.linear_query.bias", "decoder.transformer_layers.2.self_attn.final_linear.bias", "decoder.transformer_layers.2.context_attn.linear_keys.bias", "decoder.transformer_layers.2.context_attn.linear_values.bias", "decoder.transformer_layers.2.context_attn.linear_query.bias", "decoder.transformer_layers.2.context_attn.final_linear.bias", "decoder.transformer_layers.3.self_attn.linear_keys.bias", "decoder.transformer_layers.3.self_attn.linear_values.bias", "decoder.transformer_layers.3.self_attn.linear_query.bias", "decoder.transformer_layers.3.self_attn.final_linear.bias", "decoder.transformer_layers.3.context_attn.linear_keys.bias", "decoder.transformer_layers.3.context_attn.linear_values.bias", "decoder.transformer_layers.3.context_attn.linear_query.bias", "decoder.transformer_layers.3.context_attn.final_linear.bias", "decoder.transformer_layers.4.self_attn.linear_keys.bias", "decoder.transformer_layers.4.self_attn.linear_values.bias", "decoder.transformer_layers.4.self_attn.linear_query.bias", "decoder.transformer_layers.4.self_attn.final_linear.bias", "decoder.transformer_layers.4.context_attn.linear_keys.bias", "decoder.transformer_layers.4.context_attn.linear_values.bias", "decoder.transformer_layers.4.context_attn.linear_query.bias", "decoder.transformer_layers.4.context_attn.final_linear.bias", "decoder.transformer_layers.5.self_attn.linear_keys.bias", "decoder.transformer_layers.5.self_attn.linear_values.bias", "decoder.transformer_layers.5.self_attn.linear_query.bias", "decoder.transformer_layers.5.self_attn.final_linear.bias", "decoder.transformer_layers.5.context_attn.linear_keys.bias", "decoder.transformer_layers.5.context_attn.linear_values.bias", "decoder.transformer_layers.5.context_attn.linear_query.bias", "decoder.transformer_layers.5.context_attn.final_linear.bias", "decoder.transformer_layers.6.self_attn.linear_keys.bias", "decoder.transformer_layers.6.self_attn.linear_values.bias", "decoder.transformer_layers.6.self_attn.linear_query.bias", "decoder.transformer_layers.6.self_attn.final_linear.bias", "decoder.transformer_layers.6.context_attn.linear_keys.bias", "decoder.transformer_layers.6.context_attn.linear_values.bias", "decoder.transformer_layers.6.context_attn.linear_query.bias", "decoder.transformer_layers.6.context_attn.final_linear.bias", "decoder.transformer_layers.7.self_attn.linear_keys.bias", "decoder.transformer_layers.7.self_attn.linear_values.bias", "decoder.transformer_layers.7.self_attn.linear_query.bias", "decoder.transformer_layers.7.self_attn.final_linear.bias", "decoder.transformer_layers.7.context_attn.linear_keys.bias", "decoder.transformer_layers.7.context_attn.linear_values.bias", "decoder.transformer_layers.7.context_attn.linear_query.bias", "decoder.transformer_layers.7.context_attn.final_linear.bias", "decoder.transformer_layers.8.self_attn.linear_keys.bias", "decoder.transformer_layers.8.self_attn.linear_values.bias", "decoder.transformer_layers.8.self_attn.linear_query.bias", "decoder.transformer_layers.8.self_attn.final_linear.bias", "decoder.transformer_layers.8.context_attn.linear_keys.bias", "decoder.transformer_layers.8.context_attn.linear_values.bias", "decoder.transformer_layers.8.context_attn.linear_query.bias", "decoder.transformer_layers.8.context_attn.final_linear.bias", "decoder.transformer_layers.9.self_attn.linear_keys.bias", "decoder.transformer_layers.9.self_attn.linear_values.bias", "decoder.transformer_layers.9.self_attn.linear_query.bias", "decoder.transformer_layers.9.self_attn.final_linear.bias", "decoder.transformer_layers.9.context_attn.linear_keys.bias", "decoder.transformer_layers.9.context_attn.linear_values.bias", "decoder.transformer_layers.9.context_attn.linear_query.bias", "decoder.transformer_layers.9.context_attn.final_linear.bias", "decoder.transformer_layers.10.self_attn.linear_keys.bias", "decoder.transformer_layers.10.self_attn.linear_values.bias", "decoder.transformer_layers.10.self_attn.linear_query.bias", "decoder.transformer_layers.10.self_attn.final_linear.bias", "decoder.transformer_layers.10.context_attn.linear_keys.bias", "decoder.transformer_layers.10.context_attn.linear_values.bias", "decoder.transformer_layers.10.context_attn.linear_query.bias", "decoder.transformer_layers.10.context_attn.final_linear.bias", "decoder.transformer_layers.11.self_attn.linear_keys.bias", "decoder.transformer_layers.11.self_attn.linear_values.bias", "decoder.transformer_layers.11.self_attn.linear_query.bias", "decoder.transformer_layers.11.self_attn.final_linear.bias", "decoder.transformer_layers.11.context_attn.linear_keys.bias", "decoder.transformer_layers.11.context_attn.linear_values.bias", "decoder.transformer_layers.11.context_attn.linear_query.bias", "decoder.transformer_layers.11.context_attn.final_linear.bias", "decoder.transformer_layers.12.self_attn.linear_keys.bias", "decoder.transformer_layers.12.self_attn.linear_values.bias", "decoder.transformer_layers.12.self_attn.linear_query.bias", "decoder.transformer_layers.12.self_attn.final_linear.bias", "decoder.transformer_layers.12.context_attn.linear_keys.bias", "decoder.transformer_layers.12.context_attn.linear_values.bias", "decoder.transformer_layers.12.context_attn.linear_query.bias", "decoder.transformer_layers.12.context_attn.final_linear.bias", "decoder.transformer_layers.13.self_attn.linear_keys.bias", "decoder.transformer_layers.13.self_attn.linear_values.bias", "decoder.transformer_layers.13.self_attn.linear_query.bias", "decoder.transformer_layers.13.self_attn.final_linear.bias", "decoder.transformer_layers.13.context_attn.linear_keys.bias", "decoder.transformer_layers.13.context_attn.linear_values.bias", "decoder.transformer_layers.13.context_attn.linear_query.bias", "decoder.transformer_layers.13.context_attn.final_linear.bias", "decoder.transformer_layers.14.self_attn.linear_keys.bias", "decoder.transformer_layers.14.self_attn.linear_values.bias", "decoder.transformer_layers.14.self_attn.linear_query.bias", "decoder.transformer_layers.14.self_attn.final_linear.bias", "decoder.transformer_layers.14.context_attn.linear_keys.bias", "decoder.transformer_layers.14.context_attn.linear_values.bias", "decoder.transformer_layers.14.context_attn.linear_query.bias", "decoder.transformer_layers.14.context_attn.final_linear.bias", "decoder.transformer_layers.15.self_attn.linear_keys.bias", "decoder.transformer_layers.15.self_attn.linear_values.bias", "decoder.transformer_layers.15.self_attn.linear_query.bias", "decoder.transformer_layers.15.self_attn.final_linear.bias", "decoder.transformer_layers.15.context_attn.linear_keys.bias", "decoder.transformer_layers.15.context_attn.linear_values.bias", "decoder.transformer_layers.15.context_attn.linear_query.bias", "decoder.transformer_layers.15.context_attn.final_linear.bias", "decoder.transformer_layers.16.self_attn.linear_keys.bias", "decoder.transformer_layers.16.self_attn.linear_values.bias", "decoder.transformer_layers.16.self_attn.linear_query.bias", "decoder.transformer_layers.16.self_attn.final_linear.bias", "decoder.transformer_layers.16.context_attn.linear_keys.bias", "decoder.transformer_layers.16.context_attn.linear_values.bias", "decoder.transformer_layers.16.context_attn.linear_query.bias", "decoder.transformer_layers.16.context_attn.final_linear.bias", "decoder.transformer_layers.17.self_attn.linear_keys.bias", "decoder.transformer_layers.17.self_attn.linear_values.bias", "decoder.transformer_layers.17.self_attn.linear_query.bias", "decoder.transformer_layers.17.self_attn.final_linear.bias", "decoder.transformer_layers.17.context_attn.linear_keys.bias", "decoder.transformer_layers.17.context_attn.linear_values.bias", "decoder.transformer_layers.17.context_attn.linear_query.bias", "decoder.transformer_layers.17.context_attn.final_linear.bias", "decoder.transformer_layers.18.self_attn.linear_keys.bias", "decoder.transformer_layers.18.self_attn.linear_values.bias", "decoder.transformer_layers.18.self_attn.linear_query.bias", "decoder.transformer_layers.18.self_attn.final_linear.bias", "decoder.transformer_layers.18.context_attn.linear_keys.bias", "decoder.transformer_layers.18.context_attn.linear_values.bias", "decoder.transformer_layers.18.context_attn.linear_query.bias", "decoder.transformer_layers.18.context_attn.final_linear.bias", "decoder.transformer_layers.19.self_attn.linear_keys.bias", "decoder.transformer_layers.19.self_attn.linear_values.bias", "decoder.transformer_layers.19.self_attn.linear_query.bias", "decoder.transformer_layers.19.self_attn.final_linear.bias", "decoder.transformer_layers.19.context_attn.linear_keys.bias", "decoder.transformer_layers.19.context_attn.linear_values.bias", "decoder.transformer_layers.19.context_attn.linear_query.bias", "decoder.transformer_layers.19.context_attn.final_linear.bias", "decoder.transformer_layers.20.self_attn.linear_keys.bias", "decoder.transformer_layers.20.self_attn.linear_values.bias", "decoder.transformer_layers.20.self_attn.linear_query.bias", "decoder.transformer_layers.20.self_attn.final_linear.bias", "decoder.transformer_layers.20.context_attn.linear_keys.bias", "decoder.transformer_layers.20.context_attn.linear_values.bias", "decoder.transformer_layers.20.context_attn.linear_query.bias", "decoder.transformer_layers.20.context_attn.final_linear.bias", "decoder.transformer_layers.21.self_attn.linear_keys.bias", "decoder.transformer_layers.21.self_attn.linear_values.bias", "decoder.transformer_layers.21.self_attn.linear_query.bias", "decoder.transformer_layers.21.self_attn.final_linear.bias", "decoder.transformer_layers.21.context_attn.linear_keys.bias", "decoder.transformer_layers.21.context_attn.linear_values.bias", "decoder.transformer_layers.21.context_attn.linear_query.bias", "decoder.transformer_layers.21.context_attn.final_linear.bias", "decoder.transformer_layers.22.self_attn.linear_keys.bias", "decoder.transformer_layers.22.self_attn.linear_values.bias", "decoder.transformer_layers.22.self_attn.linear_query.bias", "decoder.transformer_layers.22.self_attn.final_linear.bias", "decoder.transformer_layers.22.context_attn.linear_keys.bias", "decoder.transformer_layers.22.context_attn.linear_values.bias", "decoder.transformer_layers.22.context_attn.linear_query.bias", "decoder.transformer_layers.22.context_attn.final_linear.bias", "decoder.transformer_layers.23.self_attn.linear_keys.bias", "decoder.transformer_layers.23.self_attn.linear_values.bias", "decoder.transformer_layers.23.self_attn.linear_query.bias", "decoder.transformer_layers.23.self_attn.final_linear.bias", "decoder.transformer_layers.23.context_attn.linear_keys.bias", "decoder.transformer_layers.23.context_attn.linear_values.bias", "decoder.transformer_layers.23.context_attn.linear_query.bias", "decoder.transformer_layers.23.context_attn.final_linear.bias".
I am using the following inference.yaml:
batch_size: 8192
batch_type: tokens
beam_size: 5
fp16: null
gpu: 0
log_file: translate.log
max_length: 512
model: test_3_3B/nllb-200-lora-3_3B_step_10200.pt
report_time: true
src_prefix: </s> eng_Latn
src_subword_alpha: 0.0
src_subword_model: flores200_sacrebleu_tokenizer_spm.model
src_subword_nbest: 1
src_suffix: ''
tgt_file_prefix: true
tgt_prefix: spa_Latn
tgt_subword_alpha: 0.0
tgt_subword_model: flores200_sacrebleu_tokenizer_spm.model
tgt_subword_nbest: 1
tgt_suffix: ''
transforms:
- sentencepiece
- prefix
- suffix
I installed master 1 hour ago:
-e git+https://github.com/OpenNMT/OpenNMT-py.git@07534c5b9a181d24165ab218fda986e1fff0fef4#egg=OpenNMT_py