sorry my fault, I pushed a fix.
maybe you can try on a few steps of training to make sure it works, but should be fine hopefully.
thanks for your patience.
Thank you, now it works. I also get a slight improvement in BLEU by using add_qkvbias.
This does not work with my new Lora models. It also does not work with base models.
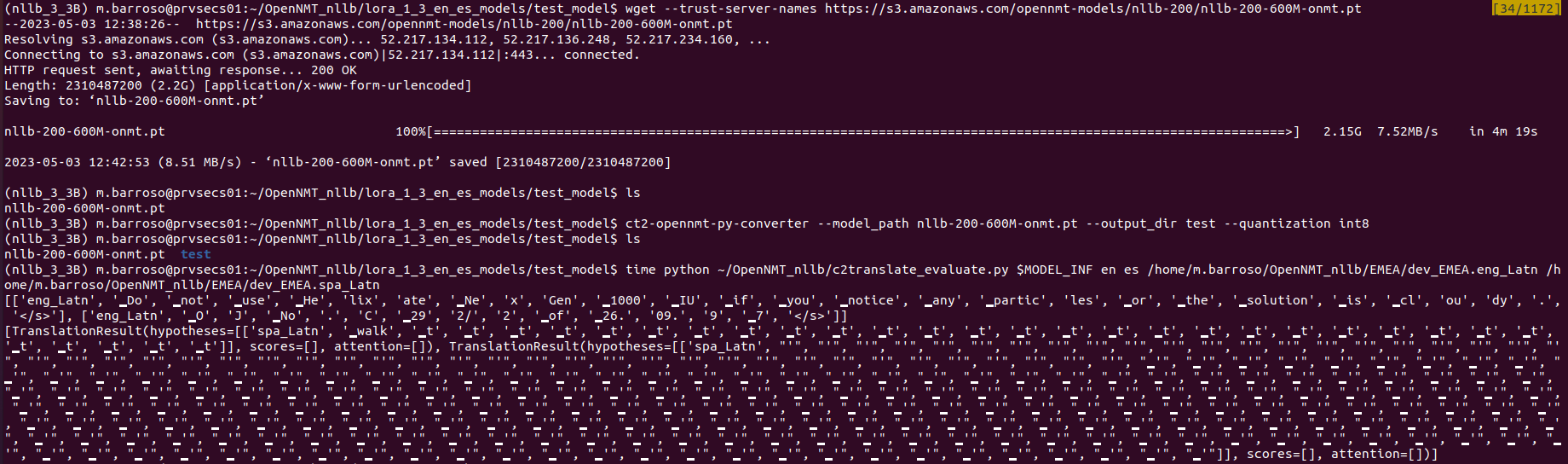
I am just executing this:
source_sents = [sent.strip() for sent in batch]
target_prefix = [[tgt]] * len(source_sents)
# Subword the source sentences
source_sents_subworded = tokenizer.encode_as_pieces(source_sents)
source_sents_subworded = [[src] + sent + ["</s>"] for sent in source_sents_subworded]
print(source_sents_subworded)
# Translate the source sentences
translations = model.translate_batch(
source_sents_subworded, batch_type="tokens", max_batch_size=1024,
beam_size=5, target_prefix=target_prefix
)
print(translations)
I tried onmt_release_model script and got the same bad results.
I have tried to do it with ctranslate2==3.11.0 and with last version (3.13.0)
Does it work when you convert the model without quantization?
I downloaded the 600M and 1.3B again and convert them without quantization. Got the same bad results. I used 3.13.0 version of ctranslate2.
did you do the exact same thing that was working with 3.11 in the other thread?
I tried both ways (old and new) and something else. All gave me the same bad results.
Seems to be a missing flag in the converted checkpoints.
I am currently uploading corrected checkpoint.
On your end you can just try the following:
import torch
m = torch.load("your checkpoint.pt")
m['opt'].decoder_start_token='</s>'
torch.save(m, "yourcheckpoint.pt")
Then you can convert to ct2.
Let me know if it fixes the issue.
That solved it, thank you so much, let us know once the original checkpoints are fixed.
they are uploaded now.
if you get a chance to try quantization int8 and int8_float16, let us know if the results are comparable.
cheers.
Tried to finetune the the 1.3B NLLB for a new language not in the NLLB model. It looks it’s working using LoRa but had to reduce the batch_size to 256. Even with this batch size there was an OOM issue at some step. Here is my config and the logs.
share_vocab: true
src_vocab: “newdictionary.txt”
src_words_min_frequency: 1
src_vocab_size: 260926
tgt_vocab: “newdictionary.txt”
tgt_words_min_frequency: 1
tgt_vocab_size: 260926
vocab_size_multiple: 1
decoder_start_token: ‘’
lora_layers: [‘linear_values’, ‘linear_query’, ‘linear_keys’, ‘final_linear’]
lora_rank: 2
lora_dropout: 0.0
lora_alpha: 1
lora_embedding: false
#Subword
src_subword_model: “flores200_sacrebleu_tokenizer_spm2.model”
tgt_subword_model: “flores200_sacrebleu_tokenizer_spm2.model”
src_subword_nbest: 1
src_subword_alpha: 0.0
tgt_subword_nbest: 1
tgt_subword_alpha: 0.0
#Corpus opts:
data:
cc-matrix-enzh:
path_src: “gmmt/en_train.txt”
path_tgt: “gmmt/gez_train.txt”
transforms: [sentencepiece, prefix, suffix, filtertoolong]
weight: 10
src_prefix: “ eng_Latn”
tgt_prefix: “gez_Ethi”
src_suffix: “”
tgt_suffix: “”
update_vocab: true
train_from: “nllb-200/nllb-200-1.3Bdst-onmt.pt.1”
reset_optim: all
save_data: “finetuned”
save_model: “finetuned/model”
log_file: “finetuned/finetuned.log”
keep_checkpoint: 50
save_checkpoint_steps: 100
average_decay: 0.0005
seed: 1234
report_every: 10
train_steps: 20000
valid_steps: 100
#Batching
bucket_size: 262144
num_workers: 2
prefetch_factor: 400
world_size: 1
gpu_ranks: [0]
batch_type: “tokens”
batch_size: 256
valid_batch_size: 256
batch_size_multiple: 1
accum_count: [32, 32, 32]
accum_steps: [0, 15000, 30000]
#Optimization
model_dtype: “fp16”
optim: “sgd”
learning_rate: 30
warmup_steps: 100
decay_method: “noam”
adam_beta2: 0.98
max_grad_norm: 0
label_smoothing: 0.1
param_init: 0
param_init_glorot: true
normalization: “tokens”
#Model
override_opts: true
encoder_type: transformer
decoder_type: transformer
enc_layers: 24
dec_layers: 24
heads: 16
hidden_size: 1024
word_vec_size: 1024
transformer_ff: 8192
dropout_steps: [0, 15000, 30000]
dropout: [0.1, 0.1, 0.1]
attention_dropout: [0.1, 0.1, 0.1]
share_decoder_embeddings: true
share_embeddings: true
position_encoding: true
position_encoding_type: ‘SinusoidalConcat’
2023-05-18 08:51:11,092 INFO] encoder: 771219456
[2023-05-18 08:51:11,092 INFO] decoder: 605397822
[2023-05-18 08:51:11,092 INFO] * number of parameters: 1376617278
[2023-05-18 08:51:11,092 INFO] * src vocab size = 260926
[2023-05-18 08:51:11,092 INFO] * tgt vocab size = 260926
[2023-05-18 08:51:11,098 INFO] Get suffix for cc-matrix-enzh: {‘src’: ‘’, ‘tgt’: ‘’}
[2023-05-18 08:51:11,098 INFO] Get suffix for src infer:
[2023-05-18 08:51:11,098 INFO] Get suffix for tgt infer:
[2023-05-18 08:51:11,186 INFO] Get prefix for cc-matrix-enzh: {‘src’: ‘ eng_Latn’, ‘tgt’: ‘gez_Ethi’}
[2023-05-18 08:51:11,186 INFO] Get prefix for src infer:
[2023-05-18 08:51:11,186 INFO] Get prefix for tgt infer:
[2023-05-18 08:51:11,186 INFO] Get suffix for cc-matrix-enzh: {‘src’: ‘’, ‘tgt’: ‘’}
[2023-05-18 08:51:11,186 INFO] Get suffix for src infer:
[2023-05-18 08:51:11,186 INFO] Get suffix for tgt infer:
[2023-05-18 08:51:11,266 INFO] Get prefix for cc-matrix-enzh: {‘src’: ‘ eng_Latn’, ‘tgt’: ‘gez_Ethi’}
[2023-05-18 08:51:11,266 INFO] Get prefix for src infer:
[2023-05-18 08:51:11,266 INFO] Get prefix for tgt infer:
[2023-05-18 08:51:11,309 INFO] Starting training on GPU: [0]
[2023-05-18 08:51:11,309 INFO] Start training loop without validation…
[2023-05-18 08:51:11,309 INFO] Scoring with: TransformPipe()
[2023-05-18 08:52:43,343 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,394 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,436 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,479 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,522 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,564 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,603 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,646 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,690 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,735 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,777 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,821 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,863 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,906 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,947 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:43,987 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:52:44,027 INFO] Step 3, cuda OOM - batch removed
[2023-05-18 08:53:40,481 INFO] Step 10/20000; acc: 87.1; ppl: 41.1; xent: 3.7; lr: 0.01031; sents: 2059; bsz: 242/ 173/ 7; 491/350 tok/s; 149 sec;
[2023-05-18 08:55:01,678 INFO] Step 20/20000; acc: 88.6; ppl: 34.7; xent: 3.5; lr: 0.01969; sents: 2012; bsz: 228/ 171/ 6; 901/673 tok/s; 230 sec;
[2023-05-18 08:56:22,381 INFO] Step 30/20000; acc: 89.0; ppl: 30.5; xent: 3.4; lr: 0.02906; sents: 2008; bsz: 231/ 172/ 6; 914/682 tok/s; 311 sec;
[2023-05-18 08:57:44,187 INFO] Step 40/20000; acc: 89.2; ppl: 26.8; xent: 3.3; lr: 0.03844; sents: 2131; bsz: 232/ 174/ 7; 907/682 tok/s; 393 sec;
[2023-05-18 08:59:05,981 INFO] Step 50/20000; acc: 90.3; ppl: 20.9; xent: 3.0; lr: 0.04781; sents: 2052; bsz: 228/ 171/ 6; 893/669 tok/s; 475 sec;
[2023-05-18 09:00:28,665 INFO] Step 60/20000; acc: 90.7; ppl: 16.7; xent: 2.8; lr: 0.05719; sents: 2109; bsz: 230/ 173/ 7; 890/671 tok/s; 557 sec;
[2023-05-18 09:01:50,481 INFO] Step 70/20000; acc: 91.4; ppl: 13.6; xent: 2.6; lr: 0.06656; sents: 2074; bsz: 230/ 172/ 6; 900/674 tok/s; 639 sec;
[2023-05-18 09:03:12,056 INFO] Step 80/20000; acc: 92.0; ppl: 11.5; xent: 2.4; lr: 0.07594; sents: 2097; bsz: 231/ 171/ 7; 906/672 tok/s; 721 sec;
[2023-05-18 09:04:33,925 INFO] Step 90/20000; acc: 92.4; ppl: 10.5; xent: 2.4; lr: 0.08531; sents: 2043; bsz: 229/ 171/ 6; 897/669 tok/s; 803 sec;
[2023-05-18 09:05:55,337 INFO] Step 100/20000; acc: 92.5; ppl: 10.1; xent: 2.3; lr: 0.09328; sents: 2030; bsz: 229/ 171/ 6; 899/672 tok/s; 884 sec;
and also you need the src_suffix: “”
1 Like
Thank you, I will use fusedadam. Why do I need the src_suffix, what is it supposed to be?
The inference failed after finetuning the the NLLB model using LoRa.
config = '''transforms: [sentencepiece, prefix, suffix]
# nllb-200 specific prefixing and suffixing
src_prefix: "eng_Latn"
tgt_prefix: "gez_Ethi"
tgt_file_prefix: true
src_suffix: "</s>"
tgt_suffix: ""
#### Subword
src_subword_model: "flores200_sacrebleu_tokenizer_spm2.model"
tgt_subword_model: "flores200_sacrebleu_tokenizer_spm2.model"
src_subword_nbest: 1
src_subword_alpha: 0.0
tgt_subword_nbest: 1
tgt_subword_alpha: 0.0
# Model info
model: "finetuned/gez_nllb_step_20000.pt"
# Inference
max_length: 512
gpu: 0
batch_type: tokens
batch_size: 384
fp16:
beam_size: 5
report_time: true'''
[2023-05-22 13:26:07,871 INFO] Adding LoRa layers for linear_values
[2023-05-22 13:26:08,784 INFO] Adding LoRa layers for linear_query
[2023-05-22 13:26:09,821 INFO] Adding LoRa layers for linear_keys
[2023-05-22 13:26:11,543 INFO] Adding LoRa layers for final_linear
Traceback (most recent call last):
File “…/OpenNMT-py/translate.py”, line 6, in
main()
File “/home/aman/Documents/geeztranslation/OpenNMT-py/onmt/bin/translate.py”, line 60, in main
translate(opt)
File “/home/aman/Documents/geeztranslation/OpenNMT-py/onmt/bin/translate.py”, line 23, in translate
translator = build_translator(opt, logger=logger,
File “/home/aman/Documents/geeztranslation/OpenNMT-py/onmt/translate/translator.py”, line 33, in build_translator
vocabs, model, model_opt = load_test_model(opt)
File “/home/aman/Documents/geeztranslation/OpenNMT-py/onmt/model_builder.py”, line 171, in load_test_model
model = build_base_model(model_opt, vocabs, checkpoint)
File “/home/aman/Documents/geeztranslation/OpenNMT-py/onmt/model_builder.py”, line 385, in build_base_model
if ‘0.weight’ in checkpoint[‘generator’]:
TypeError: argument of type ‘NoneType’ is not iterable```
Post the command lines:
- you used to merge the weights
- the translate.py full line
Sorry, I didn’t know I need to merge the weights, could share me any script related to that please.
you need to read the threads, it is just a few messages above…
1 Like
I couldn’t find the LoRa weights file, shouldn’t it be in the same location with the base model?
What you train and save with Lora options are Lora weights (files), no full models. You have to merge it with base model (model you trained from) before doing inference. You can check the different size of files.
1.3B nllb is like 5 GB while lora weights is only some MB.
1 Like
Got it, thank you for clearing my confusion!