Is there a way to filter out low quality translations?
I looked once at the score option, it produced negative log likelihood, but I wasn’t sure how to use it, because it didn’t seem to correlate with the quality of translation.
Can you check if the normalized negative log likelihood correlates better with the translation quality? (Take the negative log likelihood from the score option and divide it by the number of tokens in the translation.)
1 Like
Dear Nart,
I would be very interested in knowing how Guillaume’s suggestion works. Please keep us informed.
You might also be aware of Quality Estimation tools such as TransQuest and OpenKiwi, useful when there is no reference.
Kind regards,
Yasmin
1 Like
Dear Yasmine,
I will get this post updated with the results.
Thanks for the links!
Best regards,
Nart.
1 Like
I’m getting an error when trying to score, any ideas?
!onmt-main --config data.yml --auto_config score --features_file v7/tgt-test.txt --predictions_file v7/pred-test.txt
Here is the last part of the log:
2021-02-22 11:23:45.265267: I tensorflow/core/common_runtime/bfc_allocator.cc:1042] total_region_allocated_bytes_: 14674280960 memory_limit_: 14674281152 available bytes: 192 curr_region_allocation_bytes_: 17179869184
2021-02-22 11:23:45.265283: I tensorflow/core/common_runtime/bfc_allocator.cc:1048] Stats:
Limit: 14674281152
InUse: 10472735232
MaxInUse: 11020987904
NumAllocs: 366
MaxAllocSize: 2420000000
Reserved: 0
PeakReserved: 0
LargestFreeBlock: 0
2021-02-22 11:23:45.265312: W tensorflow/core/common_runtime/bfc_allocator.cc:441] *********************************____________**************___________*********__*******************
2021-02-22 11:23:45.265341: W tensorflow/core/framework/op_kernel.cc:1763] OP_REQUIRES failed at batch_matmul_op_impl.h:685 : Resource exhausted: OOM when allocating tensor with shape[246,8000,246] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
2021-02-22 11:23:45.264064: W tensorflow/core/framework/op_kernel.cc:1763] OP_REQUIRES failed at transpose_op.cc:184 : Resource exhausted: OOM when allocating tensor with shape[1000,8,275,275] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
Traceback (most recent call last):
File "/usr/local/bin/onmt-main", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python3.6/dist-packages/opennmt/bin/main.py", line 349, in main
checkpoint_path=args.checkpoint_path,
File "/usr/local/lib/python3.6/dist-packages/opennmt/runner.py", line 462, in score
model, dataset, print_params=score_config, output_file=output_file
File "/usr/local/lib/python3.6/dist-packages/opennmt/inference.py", line 119, in score_dataset
results = score_fn(features, labels)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py", line 828, in __call__
result = self._call(*args, **kwds)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/def_function.py", line 888, in _call
return self._stateless_fn(*args, **kwds)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 2943, in __call__
filtered_flat_args, captured_inputs=graph_function.captured_inputs) # pylint: disable=protected-access
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 1919, in _call_flat
ctx, args, cancellation_manager=cancellation_manager))
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/function.py", line 560, in call
ctx=ctx)
File "/usr/local/lib/python3.6/dist-packages/tensorflow/python/eager/execute.py", line 60, in quick_execute
inputs, attrs, num_outputs)
tensorflow.python.framework.errors_impl.ResourceExhaustedError: 2 root error(s) found.
(0) Resource exhausted: OOM when allocating tensor with shape[246,8000,246] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc
[[node transformer_base_relative_1/self_attention_decoder_1/self_attention_decoder_layer_6/transformer_layer_wrapper_42/multi_head_attention_24/MatMul_1 (defined at /lib/python3.6/dist-packages/opennmt/layers/transformer.py:112) ]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
[[transformer_base_relative_1/StatefulPartitionedCall/SelectV2/_178]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
0 successful operations.
0 derived errors ignored. [Op:__inference_score_23595]
Errors may have originated from an input operation.
Input Source operations connected to node transformer_base_relative_1/self_attention_decoder_1/self_attention_decoder_layer_6/transformer_layer_wrapper_42/multi_head_attention_24/MatMul_1:
transformer_base_relative_1/self_attention_decoder_1/self_attention_decoder_layer_6/transformer_layer_wrapper_42/multi_head_attention_24/Reshape_3 (defined at /lib/python3.6/dist-packages/opennmt/layers/transformer.py:111)
transformer_base_relative_1/self_attention_decoder_1/self_attention_decoder_layer_6/transformer_layer_wrapper_42/multi_head_attention_24/embedding_lookup/Identity (defined at /lib/python3.6/dist-packages/opennmt/layers/transformer.py:292)
Input Source operations connected to node transformer_base_relative_1/self_attention_decoder_1/self_attention_decoder_layer_6/transformer_layer_wrapper_42/multi_head_attention_24/MatMul_1:
transformer_base_relative_1/self_attention_decoder_1/self_attention_decoder_layer_6/transformer_layer_wrapper_42/multi_head_attention_24/Reshape_3 (defined at /lib/python3.6/dist-packages/opennmt/layers/transformer.py:111)
transformer_base_relative_1/self_attention_decoder_1/self_attention_decoder_layer_6/transformer_layer_wrapper_42/multi_head_attention_24/embedding_lookup/Identity (defined at /lib/python3.6/dist-packages/opennmt/layers/transformer.py:292)
Function call stack:
score -> scoreThis is an out-of-memory error. You probably have very long lines in your test file that should be cleaned up.
I will check it out.
But that wasn’t an issue during inference, or training.
Does scoring support batch_type: token?
@ymoslem @guillaumekln
Normalized negative log likelihood of the translated sentences doesn’t seem to correlate with translation quality.
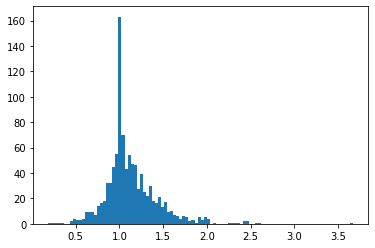
Something else seems to correlate though, the ratio between negative log likelihood of the label sentences and the translated sentences:
ratio = negative log likelihood (labels) / negative log likelihood (translated)
(i.e) Negative log likelihood (labels):
onmt-main --config data.yml --auto_config score --features_file tgt-test.txt --predictions_file tgt-test.txt > score_labels.txt
Negative log likelihood (translated):
onmt-main --config data.yml --auto_config score --features_file tgt-test.txt --predictions_file tgt-translated.txt > score_translated.txt
Here is a histogram of the ratio that shows correlation:
2 Likes
Interesting, thanks for sharing!
No, but we should probably add that.
EDIT:
1 Like