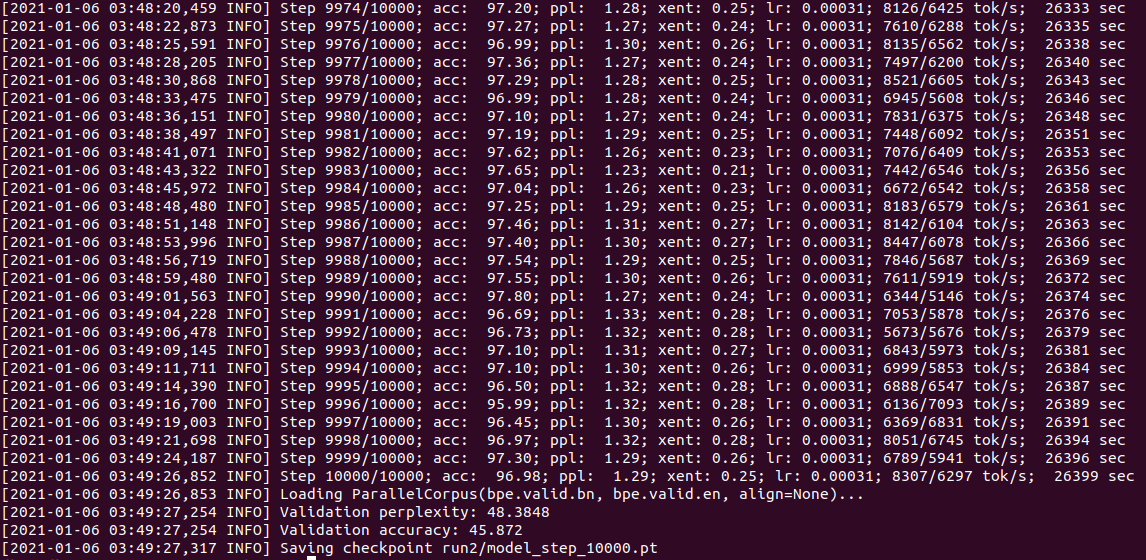
Hello , I am using OPenNMT for my research purpose . In our paper ,we would like to make a comparison where we need to know about every keywords we will be talking about . I would like to know about following words and their functionality :
**acc (I guess its the accuracy of training set…if i am wrong please correct me )
**ppl (I dont know about it)
**xent (I dont know about it)
**lr (I guess its the rate how fast or slow my model is getting learnt …if i am wrong please correct me)
**validation accuracy (I guess its the accuracy of validation set…if i am wrong please correct me )
***validation perplexity (I dont know about it)
and another question : I am using warmup steps same as my training steps for transformer model . Will it make any difference or I would like to know will my model be accepted??
I am sorry if I ask some silly questions .Thanks Beforehand
Best ,
Argha Dhar