Hello,
you can find on this repo (branch “extract-inject”) a version of OpenNMT-tf that allows extraction and precise replacement of attention weights in Transformer encoders, which is the result of my internship at Systran.
This allows visualization of self-attention, as well as more systematic studies. It also allows the user to inject perturbations in the self-attention, with those perturbations depending on the input sentences.
There are also scripts for :
- analysis of the self-attention encoder heads syntactic roles based on most attended token.
- experiments with different modifications of self-attention as a function of the syntactic properties of the sentence.
These scripts can be found in the scripts/tweak_attn directory.
With these, I could imitate experiments from Voita et al. on the syntactic functions of heads. I have been able to identify heads focusing on different syntactic dependencies as well as constant relative positions in a Transformer trained on French -> German translation at Systran.
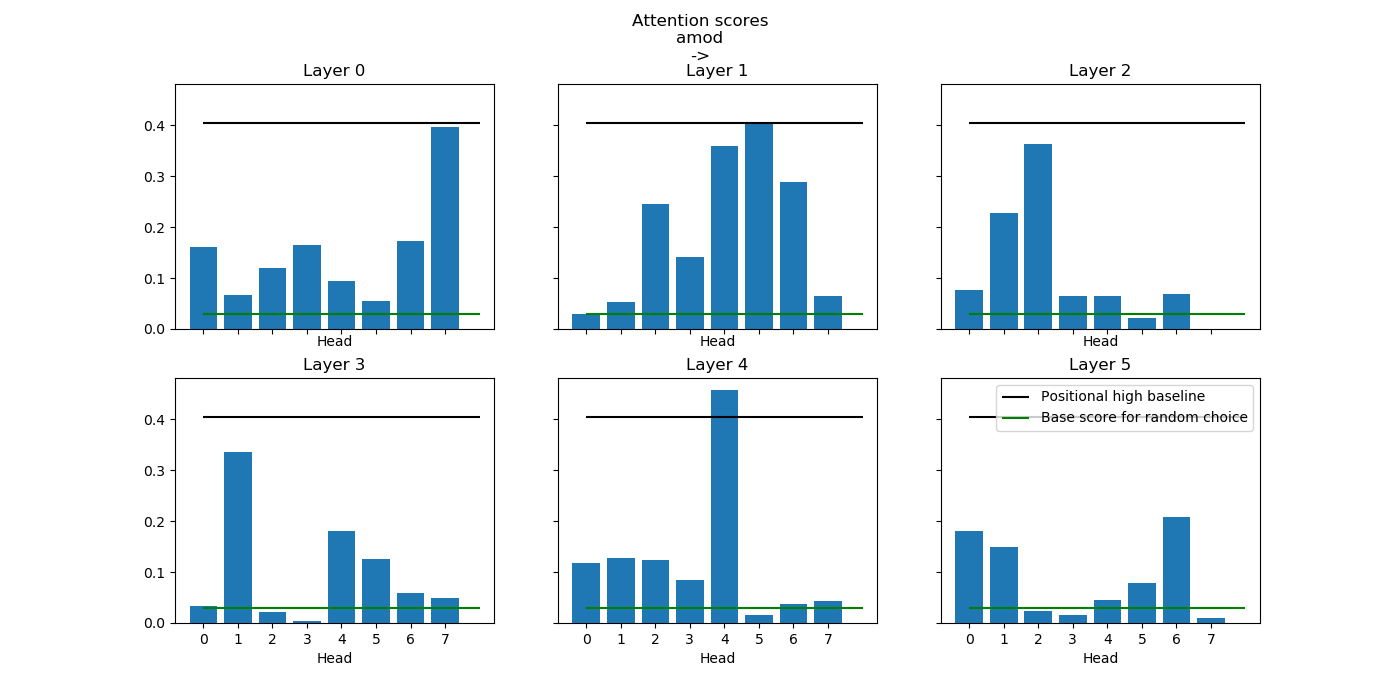
Scores of self-attention heads for adjective->noun attention.
I could also find that the focus seldom varies with syntactic properties of words such as gender or number. One exception is the verb voice, which noticeably impacts the attention between subject and verb on several heads.
There is work in progress on injecting attention in syntactic heads previously identified to try and change the syntactic properties of the translation, with in mind the possibility of eventually improving translation by injecting syntactic information when available.
All comments or feedback are appreciated, and please let me know if you find something interesting using this !