Hello everyone,I am trying to translate from English to Chinese.There are 14005403 training sets and 44298 verification sets.Here is my process.
1.Using nltk.word_tokenize participle in English,Chinese uses Jieba participle.
2.Use fast_align for word alignment and delete Chinese and English sentence pairs with alignment ratio less than 1/2
Some of the data after processing are as follows:
in recent years , the frequency and magnitude of major disasters , whether of a natural , technological or ecological origin , have made the world community aware of the immense loss of human life and economic resources that are regularly caused by such calamities .
15 . 最近 几年 , 由 自然 、 技术 或 生态 造成 的 灾害 的 频繁 程度 和 规模 使 国际 社会意识 到 由于 此类 灾害 经常 对 人 的 生命 和 经济 资源 造成 的 巨大损失 。
particularly hard hit are developing countries , for which the magnitude of disasters frequently outstrips the ability of the society to cope with them .
发展中国家 特别 深受其害 , 对 它们 而言 , 灾害 的 规模 经常 超出 了 它们 应付 的 能力 。
it was stated that this was due to the fact that 95 per cent of all disasters occurred in developing countries .
据称 这 是因为 在 所有 的 灾害 中 95% 发生 在 发展中国家 。
3.Finally, openNMT-py is used to preprocess and train.
This is my training parameter.
python train.py -data $model -save_model ./demo-model -batch_size=32 -learning_rate=0.1 -train_steps=600000 -gpu_ranks 0
4.Translation result
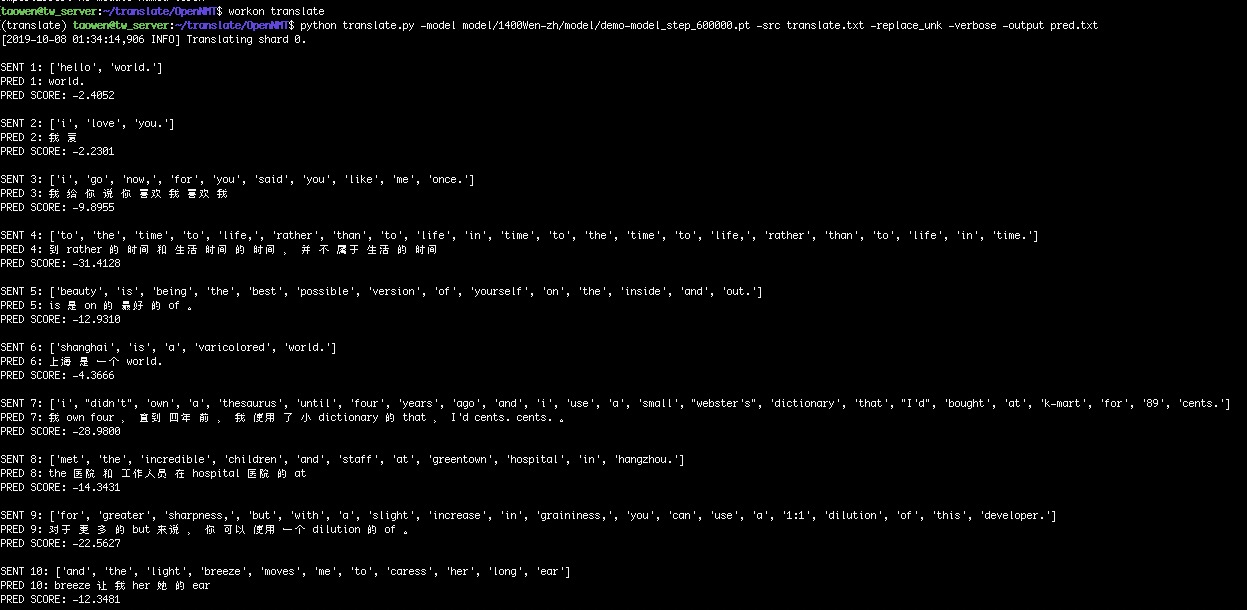
The result of translation is not very satisfactory. Is there a better plan? Thank you for your comments.
In addition, if there is a good Chinese-English model, I would like to buy it.