Why do I get different results on the same model when translating with CPU and GPU?
English - Marathi
English: Please speak more slowly
Marathi (CPU): कृपया धीरे धीरे बोल
Marathi (GPU): कृपया आणखी धीरे बोल
English: Yes, a little
Marathi (CPU): होय, थोडे
Marathi (GPU): हो, थोडे
English: We go
Marathi (CPU): आपण जाऊया
Marathi (GPU): आपण जातो
Can you provide more details?
What framework do you use? What’s the model and options?
I apologize for the long reply. We decided to do more tests to make sure the experiment is clean.
We use OpenNMT-tf 2.31.0
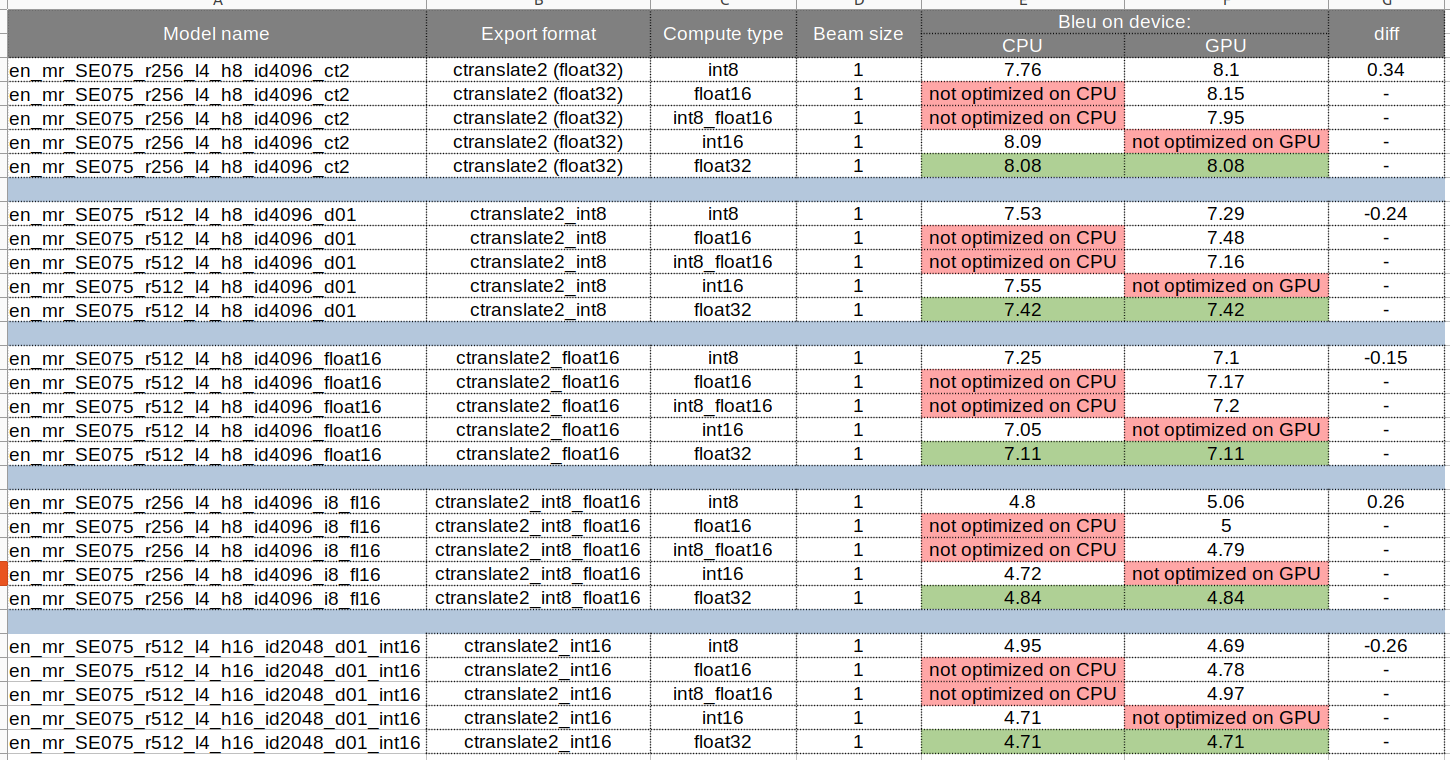
Based on our experiments we came to the conclusion that the difference in translation on CPU and GPU occurs when we use the quantization format when loading the model - “int8” (Compute type).
This is mostly expected.
Numerical results will necessarily differ between the CPU and GPU runtime, especially when running in reduced precision like int8 because small numerical variations can be amplified by the quantization.
Only running the model in full precision (float32) can minimize the translation differences.
1 Like