Part II - The starting point
“Capacity for information is the key. Machines will absorb not only more raw data, but more feelings, as soon as we understand them. When that happens we will be able to love and hate far more passionately than humans. Our music will be greater, our paintings more magnificent. Once we achieve complete self-awareness, thinking machines will create the greatest renaissance in history.”
— Erasmus, Legends of Dune
The original experiment
The original paper, published in 2009, is using a very simple and tiny (for today standard) neural network as described in the following figure:
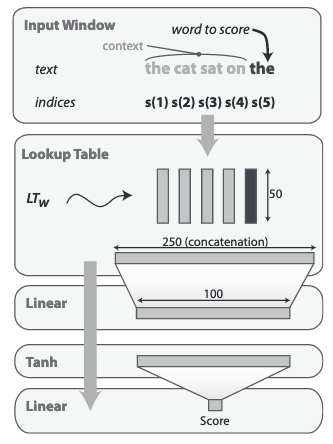
Unlike precedent approaches on neural language modeling and following (Collobert, 2008), this language model is not trying to predict the probability of the word to score, but is instead implementing a max-margin loss function and using ranking as an evaluation criterion.
The max-margin loss function is defined by the following equation:
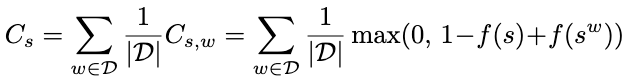
where s is the word we are scoring (last word of the window) and w is a counter-example word that is randomly sampled from the vocabulary - and the loss formula simply tries to push the score of the context with this random word w, being at least 1 smaller than the score of the context with the original word s. This naturally teaches the neural network to rank the possible words that can follow the context. The higher score, the most likely.
The evaluation of the performance of the network is then naturally performed using a ranking criterion: evaluated on all the possible vocabs following a given context, what is the rank of the actual word ?
This simple architecture has been a key milestone in word embeddings development since the most of the parameters of the network are for the lookup table (1M parameters for a 20k vocab, compared to 25100 additional parameters composing the 2 downstream dense layers) - what the model learn is basically a good word vector representation fitting the ranking task.
The training process is pretty straight forward: in the original paper, vocabulary are lowercased plain words, limited to 20k most frequent. The training corpus is 2008 English wikipedia, making 631M 5-word windows (excluding windows with out of vocabulary tokens).
The baseline training (no-curriculum) is running for ~3 full epochs on the training corpus, iteratively sampling pairs of (s,w) used to compute loss for standard SGD optimization.
In constrat, the Curriculum Learning performs 3 iterations on the same data, but for each iteration, the vocabulary is limited to 1/ the top most frequent 5000 words, 2/ the top most frequent 10000 words, and then the full vocabulary. In each of these iterations, the training windows is therefore limited to the windows with only tokens part of these restricted vocabulary (respectively 270M, 370M, 638M). For the evaluation, the complete vocabulary is of course kept.
The results are the following:
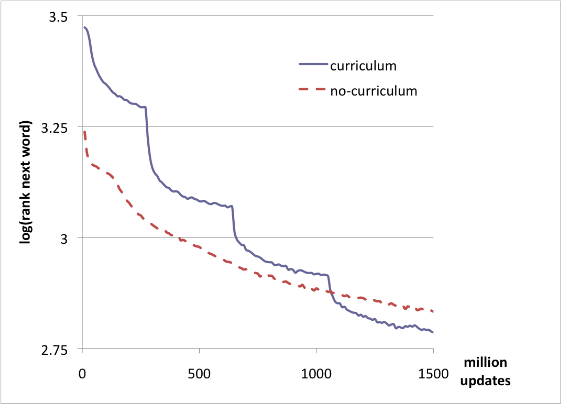
The authors conclude: “we observe that the log rank on the target distribution with the curriculum strategy crosses the error of the no-curriculum strategy after about 1 billion updates, shortly after switching to the target vocabulary size of 20,000 words, and the difference keeps increasing afterwards. The final test set average log-ranks are 2.78 and 2.83 respectively, and the difference is statistically significant”.
Interpretation of the result:
- we can clearly see the different phases of the training in the “curriculum” curve. In particular, we can see that the model slows down at the end of each intermediate phase: this is expected, the model does not know yet the complete vocabulary so is totally unable to guess the rank of training-unknown vocabs (for which the lookup table is still totally random).
- After 1500 million updates, for both models, the learning has still not completed. The average logrank is around 2.8 corresponding to a rank of ~16 (
 the average of the logrank is not corresponding to the log of the average rank, so the average rank is not as good as ~16)
the average of the logrank is not corresponding to the log of the average rank, so the average rank is not as good as ~16)
- On the no-curriculum curve, we can see a first phase (between 0-100M updates) where the learning seems to slow down before restarting more steadily. The same effect can be observed at the very beginning of the curriculum curve - I will give more light on this effect in my own experiment
- The paper does not indicate why they can conclude the difference is statistically significant - however, we must note that the difference is corresponding to about 1 position for non-log ranking (16.12 vs 16.95). It is a win but not a huge win and we can suppose that the two models would have eventually converged to the same value. However, we can also see that the final value after 1500 million updates for the non-curriculum curve is reached around 1100 million updates only for the curriculum curve. So the acceleration of the training is here really significant (2-days win out of a reported 7-day training time).
Last, it is interesting to note that the model is really tiny in our 2020 standard, with 1M parameters, the model is 500-1000 times smaller than a real scale transformer model!
My reproduction of the experiment
For fairness of the recent paper reproduction process, I did reproduce the same network and experiment. The commented code is here.
However, to reduce the differences with following experiments on Neural Machine Translation, I am using the same preprocessed English corpus as the one for the reference WMT English-German training defined here. The details are:
- Corpus - 4.5M sentences from:
- Preprocessing: Sentence Piece with 32k vocabulary
For the LM training with 20k top vocabs, this makes a total of 117M 5-token windows.
Let us note that working with sentence piece tokens, the scoring task with 4 context token (only!) is far more complicated since the actual context is smaller than the 4 full words in the original experiment, also the actual covered vocabulary is far larger (20k out of the total 32k sentence piece vocab compared to 20k words out of … 840791 different tokens on simple lowercased tokenized corpus). So we expect the Language Model to struggle far more.
For instance for the sentence “Airbus says the competing version of its A350 will carry 350 people in 18-inch-wide economy seat laid out 9 abreast.”, OOV and the extracted windows will be:
|
Sentence Piece (top 20k vocab) |
Simple Tokenization (top 20k vocab) |
| OOV |
|
a350, 18-inch-wide
|
| windows |
▁Airbus ▁says ▁the ▁competing ▁version
▁says ▁the ▁competing ▁version _of
▁the ▁competing ▁version _of _its
▁competing ▁version _of _its _A
▁version _of _its _A 350
▁of ▁its ▁A 350 ▁will
▁its ▁A 350 ▁will _carry
▁A 350 ▁will _carry _350
350 ▁will _carry _350 _people
▁will _carry _350 _people _in
▁carry ▁350 ▁people ▁in ▁18
▁350 ▁people ▁in ▁18 -
▁people ▁in ▁18 - in
▁in ▁18 - in ch
▁18 - in ch -
- in ch - wide
in ch - wide ▁economy
ch - wide _economy ▁seat
- wide _economy _seat ▁laid
wide _economy _seat _laid ▁out
_economy _seat _laid _out ▁9
_seat _laid _out _9 ▁a
_laid _out _9 _a bre
_out _9 _a brea ast
_9 _a brea ast .
|
airbus says the competing version
says the competing version of
the competing version of its
will carry 350 people in
economy seat laid out 9
seat laid out 9 abreast
laid out 9 abreast .
|
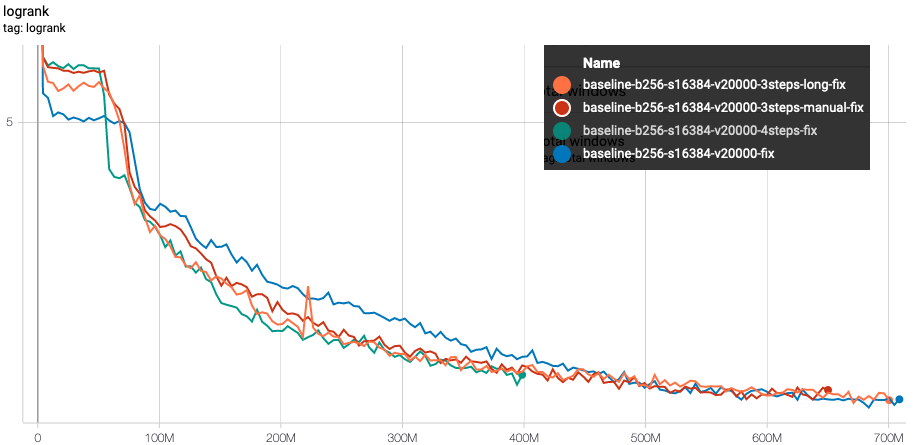
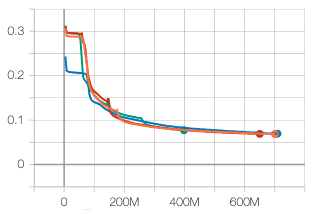
The results directly exported from tensorboard are represented by the following graph:
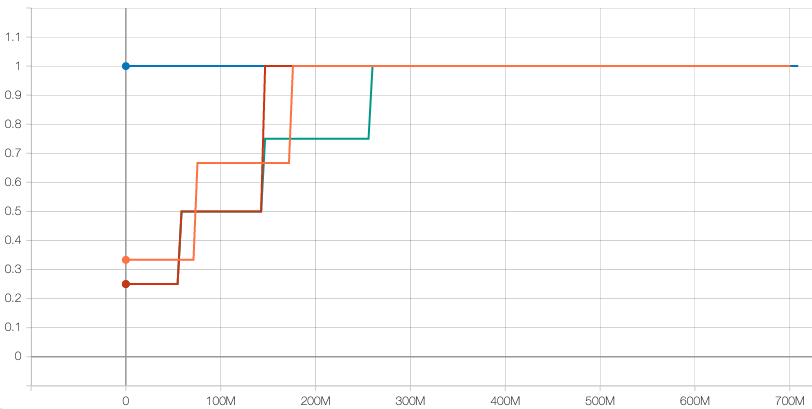
These graphs show the longrank evolution with the number of presented examples - the difference between each experiments is the covered vocabulary evolution as represented by the following graph:
- the blue curve does not select the windows based on vocabulary: from the very first updates, all examples are used to train the model
- the curve 3-steps-manual (red), is following exactly the curriculum of the paper: during a first pass on the complete corpus, only windows containing most frequent 5000 vocabs are selected (about 71M windows), then in the second phase, the windows with the 10000 most frequent vocabs (about 100M windows), and afterward, all of the windows are preserved.
- the green line is following a uniform 4-steps curriculum adding last phase limited to windows with top-15000 vocab windows
The parameters used for this experiment are given by the following configuration:
batch_size = 256
steps_per_epoch = 16384
sgd_learning_rate = 0.01
sgd_momentum = 0.9
sgd_decay = 1e-06
buffer_size = 500000
vocab = 20000
include_unk = False
window_size = 5
embedding_size = 50
dense_size = 100
Exactly like the results of the paper, we observe the same impact of the curriculum learning.
- In the very first phase(s), the performance of curriculum-learning runs are worse than baseline. This is totally expected since the model is only trained with a limited vocabulary, and is therefore totally ignorant when dealing with windows of the test set with rare vocabs.
- Everytime the vocabulary increases, the learning speeds up - and quickly catch-up with the full-vocab learning
- All of the experiments with curriculum learning start the last phase of their training with a huge head start on the baseline training. At only 200M updates, the 3 curriculum-learning experiments have the score that the baseline reaches after 300M updates.
As hypothetized however, the heads up given by the curriculum learning is gradually reducing and is eventually totally wearing out.
Some independent effect that is more clearly seen on this experiment is that the very first phase of the learning seems to stall before finally kicking out around 50M updates. During this initial phase, very clear on the training loss evolution below and that we can also observe looking at the test outputs, the model seems to just be learning to sort the vocabs which is indeed a easy first quick win.
Some examples of ranked tokens after 50M updates:
| Context |
w |
rank of w
|
#1 |
#2 |
#3 |
#4 |
#5 |
#6 |
#7 |
▁But ▁the ▁victim ' |
s |
3 |
. |
, |
s |
- |
▁and |
▁in |
' |
▁would ▁want ▁to ▁hurt |
▁him |
176 |
. |
, |
▁of |
▁to |
▁in |
▁and |
▁the |
▁line ▁cook ▁in ▁Boston |
, |
2 |
. |
, |
▁of |
▁in |
- |
s |
▁and |
Conclusion
The Curriculum Learning as presented by the original paper is fully reproduced in our experiment even if our task is harder than the one in the original paper. The main effect of the Curriculum Learning is a huge boost on the convergence speed but we are also showing that for that experiment, training without Curriculum Learning and training with Curriculum Learning are eventually reaching the same performance.
The questions that we will be trying to answer in our following posts are if the same can work with modern neural network architecture and with tasks like Neural Machine Translation…
 ?
?