I have been working to training a multilingual model, using a huge corpa but, even after using 8GPUs I am still getting out of memory error.
Here is my config file:
save_data: run/
src_vocab_size: 500000
tgt_vocab_size: 500000
# to prevent out of memory error
src_seq_length: 70
tgt_seq_length: 70
src_vocab: run/vocaben.src
tgt_vocab: run/vocabde.tgt
overwrite: True
# corpus post
data:
corpus_1:
path_src: data/description/pattr.de-en.description.en
path_tgt: data/description/pattr.de-en.description.de
corpus_2:
path_src: data/abstract/pattr.de-en.abstract.en
path_tgt: data/abstract/pattr.de-en.abstract.de
corpus_3:
path_src: data/claims/pattr.de-en.claims.en
path_tgt: data/claims/pattr.de-en.claims.de
valid:
path_src: data/valid/engvalid.txt
path_tgt: data/valid/germanvalid.txt
# to train the model
world_size: 8
gpu_ranks: [0,1,2,3,4,5,6,7]
# Batching
queue_size: 10000
bucket_size: 32768
batch_type: "tokens"
batch_size: 128
valid_batch_size: 128
batch_size_multiple: 1
max_generator_batches: 0
accum_count: [3]
accum_steps: [0]
# Optimization
model_dtype: "fp32"
optim: "adam"
learning_rate: 2
warmup_steps: 8000
decay_method: "noam"
adam_beta2: 0.998
max_grad_norm: 0
label_smoothing: 0.1
param_init: 0
param_init_glorot: true
normalization: "tokens"
# Model
encoder_type: transformer
decoder_type: transformer
enc_layers: 3
dec_layers: 3
heads: 8
rnn_size: 512
word_vec_size: 512
transformer_ff: 2048
dropout_steps: [0]
dropout: [0.1]
attention_dropout: [0.1]
average_decay: 0.0005
seed: 1234
save_model: models8gpu/
save_checkpoint_steps: 2000
train_steps: 100000
valid_steps: 5000
Also, here is the image of out of memory error:
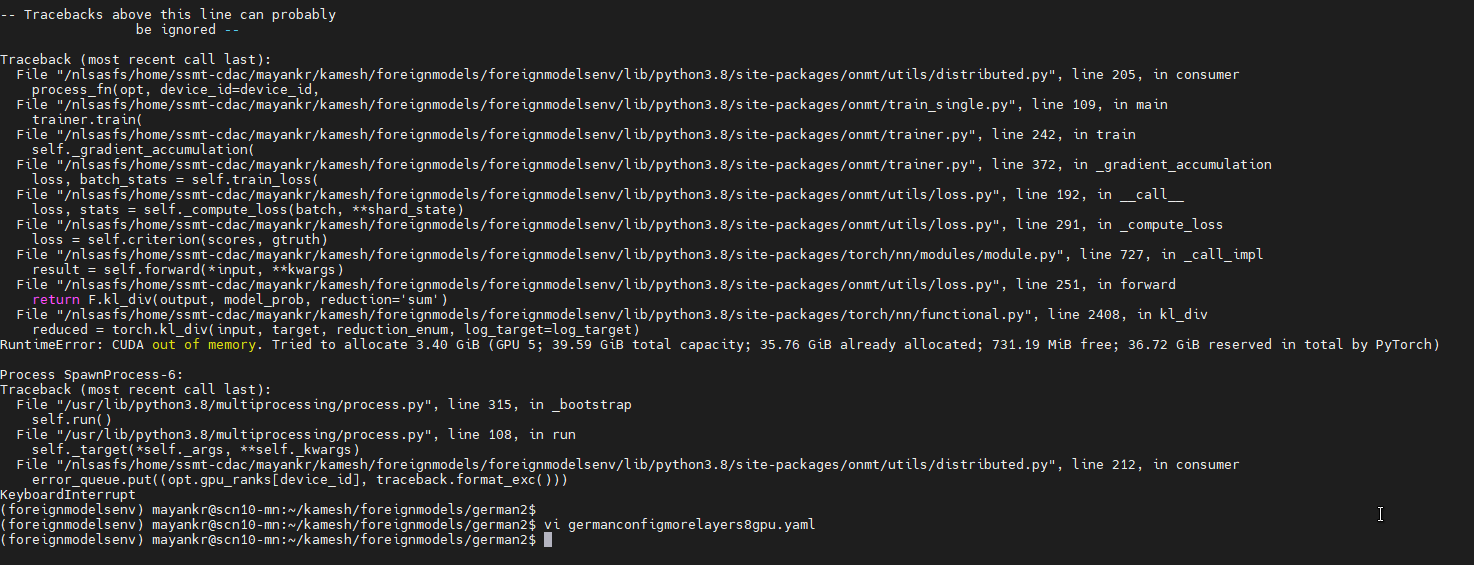
I need some help to fix it.