Hi there!
I’d like to post an update about recent additions to CTranslate2. The last similar post was in June 2021 when we released the version 2.0, so I figured it would be interesting to summarize the latest changes. It turns out there are many!
Python wheels for Windows and Linux ARM
In addition to Linux and macOS, we now also build and publish Python wheels for Windows and Linux ARM. The Windows wheels have the same level of features as the Linux ones, including GPU support.
Converter for Marian models and the collection 1000+ pretrained models from OPUS-MT
By design, CTranslate2 can run models trained by different NMT toolkits. We added a converter for Marian, in particular to make the 1000+ pretrained models from OPUS-MT usable in CTranslate2. The conversion is easy and does not require additional dependencies:
ct2-opus-mt-converter --model_dir opus_model --output_dir ct2_model
(If you are using one of these pretrained models in your application, make sure to respect their CC BY 4.0 license.)
This work also enables proper performance benchmarks with Marian as we can compare the translation speed using exactly the same model. See the benchmark table for a comparison (tl;dr: CTranslate2 is faster and uses much less memory).
M2M-100 multilingual model
Similarly, we extended the Fairseq converter to support the M2M-100 multilingual model. Check out this tutorial by @ymoslem for how to convert and use this model.
Methods to score existing translations
Scoring is sometimes used in the model training procedure, for example to filter the training data, so there are benefits in making this task fast. We added the methods Translator.score_batch and Translator.score_file.
Source factors (a.k.a. source features)
Models trained with source factors are now supported since it was requested multiple times. To simplify their integration, the source factors should be attached to the tokens directly. There is no separate argument.
In API:
translator.translate_batch([["hello│C", "world│L", "!│N"]])
In text file:
hello│C world│L !│N
There is an error if the number of factors does not match what the model expects.
Asynchronous translations from Python
You can now run asynchronous translations from Python. In this mode, Translator.translate_batch returns immediately and you can retrieve the results later:
async_results = translator.translate_batch(batch, asynchronous=True)
async_results[0].result() # This method blocks until the result is available.
Asynchronous translation is also one way to benefit from inter_threads or multi-GPU parallelism.
New translation options
Some new translation options were added:
-
disable_unk: disallow the generation of the<unk>token. -
max_input_length: truncate the inputs after this many tokens in order to limit the maximum memory usage (1024 by default). -
repetition_penalty: penalize the tokens that were already generated as described in Keskar et al. 2019.
Performance and correctness improvements
And of course, we are always looking to further increase the translation speed and reduce the memory usage. Since version 2.0, many small optimizations were implemented especially on GPU:
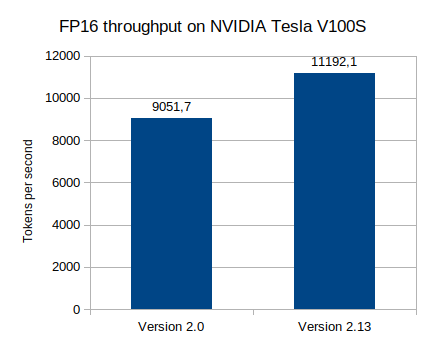
We also improved the correctness of the quantization formula. The impact is very subtle but the numerical results are more accurate. The new formula is only used for models converted after version 2.12.
What’s next?
I feel like language models, especially generative language models, are a natural continuation for this project. Technically the model support is there, but I would need to think about an integration that makes sense.
What are your ideas for CTranslate2? Is there anything you would like to see improved or think is missing from the current implementation? Thanks!