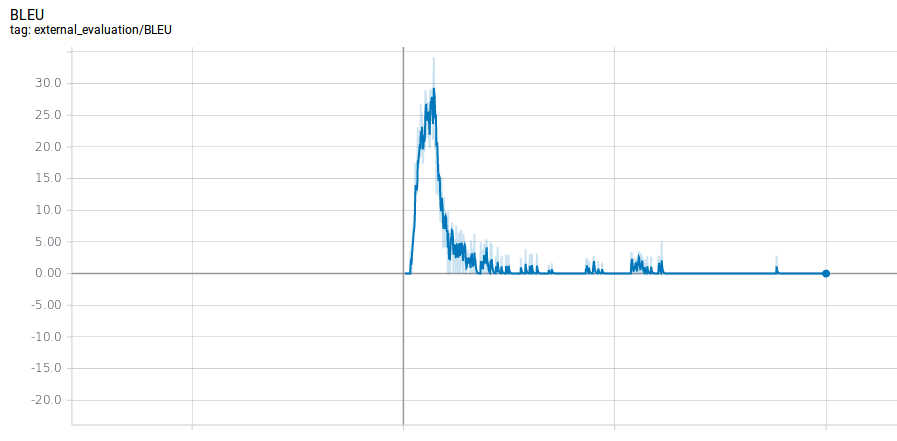
I use tokenized europarl v7 corpus for training, and tokenized WMT News news-test2013 for evaluation. For time saving, I use only the first 10 sentences in this evaluation dataset. The configuration is at the end of this post.
At the beginning (of course, after a few checkpoints, say at ckpt-5000), the BLEU score looked fine (it increased, and had been at about 9.0). But after one night, at ckpt-70000, the BLEU score became 0.
With a relative small dataset (2M sentences), is this situation expected? Or there is something wrong in my setting?
The following are target sentences and predictions at about ckpt-5000 and ckpt-70000
target: A Republican strategy to counter the re-election of Obama
ckpt-5000: An interim strategy for combating <unk> is <unk> .
ckpt-70000: This is an important issue .
target: Unlike in Canada , the American States are responsible for the organisation of federal elections in the United States .
ckpt-5000: On the contrary , the American States are responsible for elections in the United States .
ckpt-70000: The European Union ’ s security policy is a good example of the European Union .
target: Republican leaders justified their policy by the need to combat electoral fraud .
ckpt-5000: The political leaders of their political leaders have to fight against fraud .
ckpt-70000: The vote will take place tomorrow at 12 noon .
And the following are the 10 predictions at ~ckpt0-70000, which seems strange:
This is an important issue .
The vote will take place tomorrow at 12 noon .
It is also important that the European Union has a duty to do so .
I would like to thank the rapporteur for his excellent work .
It is a matter of urgency .
It is also important for the European Union to play a leading role in this area .
The European Union ’ s security policy is a good example of the European Union .
It is also important to ensure that the European Union ’ s security policy .
The Commission ’ s proposal for a directive on the implementation of the Lisbon Strategy .
The European Union ’ s security strategy is a key issue .
# The directory where models and summaries will be saved. It is created if it does not exist.
model_dir: Model/TransformerBig/
data:
# (required for train_and_eval and train run types).
train_features_file: Data/Training/Tokenized/europarl-v7.fr-en.fr_tokenized
train_labels_file: Data/Training/Tokenized/europarl-v7.fr-en.en_tokenized
# (required for train_end_eval and eval run types).
eval_features_file: Data/Evaluation/Tokenized/newstest-2013.fr_tokenized.txt
eval_labels_file: Data/Evaluation/Tokenized/newstest-2013.en_tokenized.txt
# (optional) Models may require additional resource files (e.g. vocabularies).
source_words_vocabulary: fr-vocab-30000-tokenized.txt
target_words_vocabulary: en-vocab-30000-tokenized.txt
# source_tokenizer_config: config-tokenization.yml
# target_tokenizer_config: config-tokenization.yml
params:
gradients_accum: 1
# Training options.
train:
batch_size: 3000
# (optional) Batch size is the number of "examples" or "tokens" (default: "examples").
batch_type: tokens
# (optional) Save a checkpoint every this many steps.
save_checkpoints_steps: 100
# (optional) How many checkpoints to keep on disk.
keep_checkpoint_max: 10
# (optional) Save summaries every this many steps.
save_summary_steps: 100
# (optional) Train for this many steps. If not set, train forever.
train_steps: 100000
# (optional) The number of threads to use for processing data in parallel (default: 4).
num_threads: 4
# (optional) The number of elements from which to sample during shuffling (default: 500000).
# Set 0 or null to disable shuffling, -1 to match the number of training examples.
sample_buffer_size: 0
# (optional) Number of checkpoints to average at the end of the training to the directory
# model_dir/avg (default: 0).
average_last_checkpoints: 0
# (optional) Evaluation options.
eval:
# (optional) The batch size to use (default: 32).
batch_size: 10
# (optional) The number of threads to use for processing data in parallel (default: 1).
num_threads: 4
# (optional) Evaluate every this many seconds (default: 18000).
eval_delay: 0
# (optional) Save evaluation predictions in model_dir/eval/.
save_eval_predictions: True
# (optional) Evalutator or list of evaluators that are called on the saved evaluation predictions.
# Available evaluators: BLEU, BLEU-detok, ROUGE
external_evaluators: [BLEU]
# (optional) Model exporter(s) to use during the training and evaluation loop:
# last, final, best, or null (default: last).
exporters: last