Bitextor is a tool to automatically harvest bitexts from multilingual websites. To run it, it is necessary to provide:
- The source where the parallel data will be searched: one or more websites (namely, Bitextor needs website hostnames or WARC files)
- The two languages on which the user is interested: language IDs must be provided following the ISO 639-1
- A source of bilingual information between these two languages: either a bilingual lexicon (such as those available at the bitextor-data repository), a machine translation (MT) system, or a parallel corpus to be used to produce either a lexicon or an MT system (depending on the alignment strategy chosen, see below)
Pipeline description
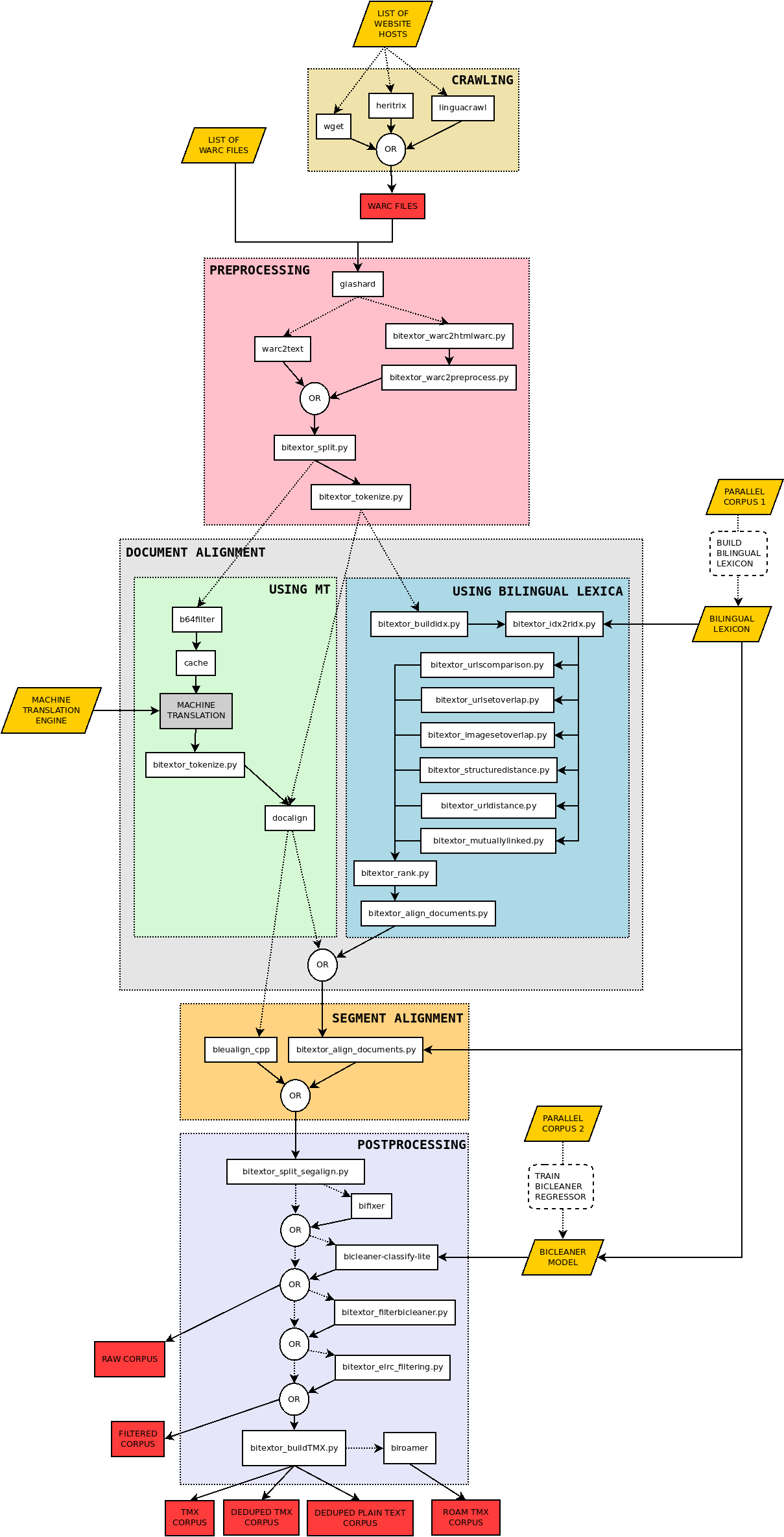
Bitextor is a pipeline that runs a collection of scripts to produce a parallel corpus from a collection of multilingual websites. The pipeline is divided in five stages:
- Crawling: documents are downloaded from the specified websites
- Pre-processing: downloaded documents are normalized, boilerplates are removed, plain text is extracted, and language is identified
- Document alignment: parallel documents are identified. Two strategies are implemented for this stage:
- one using bilingual lexica and a collection of features extracted from HTML; a linear regressor combines these resources to produce a score in [0,1], and
- another using machine translation and a TF/IDF strategy to score document pairs
- Segment alignment: each pair of documents is processed to identify parallel segments. Again, two strategies are implemented:
- one using the tool Hunalign, and
- another using Bleualign, that can only be used if the MT-based-document-alignment strategy is used (machine translations are used for both methods)
- Post-processing: final steps that allow to clean the parallel corpus obtained using the tool Bicleaner, deduplicates translation units, and computes additional quality metrics
The following diagram shows the structure of the pipeline and the different scripts that are used in each stage: