Please bring bidirectional transformer to OpenNMT-tf as soon as possible. You guys always implement things fast but though, BERT has been so much in the news. Still the feature is not there in OpenNMT when it should be at the highest priority.
Also for opennmt-py, thanks very much.
A recent research got good results with cross-lingual models.
What do you think about BERT as a parallel Input feature for the complete sentence? For the pytorch Version we could use (optional) LASER as multilingual sentence embedding.
We also could use bert-as-a-service for contextual word embeddings or pytorch word embeddings. But then we should figure out which layer we use:

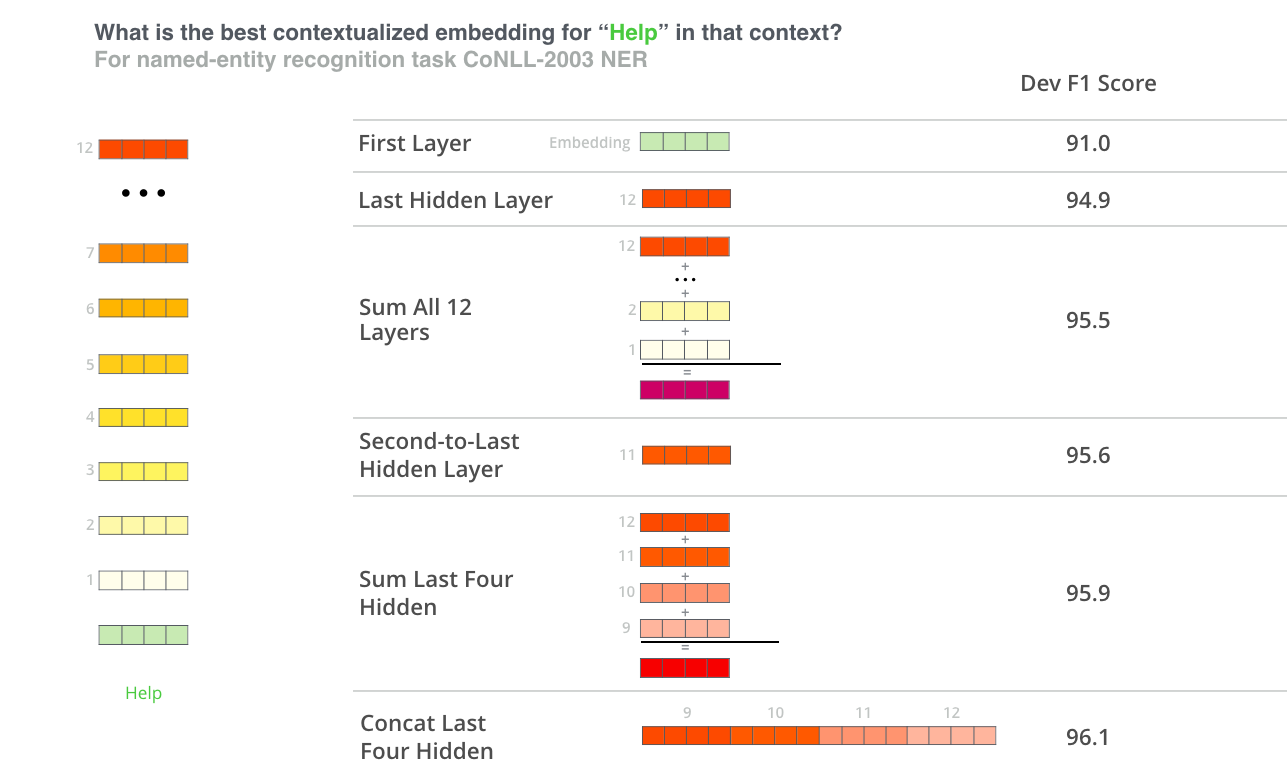
The concatenation of the layers should be a good start due to the results in the named entity recognition task: (the source is the illustrated bert)
Gonçalo M. Correia and André F. T. Martins (DeepSPIN) used in A Simple and Effective Approach to Automatic Post-Editing with Transfer Learning the multilingual Bert as encoder and initialized the context attention of the decoder with BERT’s self-attention and tied together the parameters of the self-attentionlayers between the encoder and decoder. They used openNMT as framework and open-sourced the research.
The constructed multi-source architecture is also benefited for NMT, but a large polyglot system with hundred source encoders for each language in BERT would be too heavy. So I suggest to build on this research and fitting only a language family in each source encoder or cut the multi source for the beginning. This architecture would also answer the question which layer we should use.
There is also a discussion BERT model for Machine Translation with a test for fairseq.