I’ve been playing around, testing different parameters for Ctransalte2 to get the most out of it.
Please take notes that for all the results below, my models were trained with (export_format: ctranslate2_int8 and beam_width: 15) and the execution time was real time (not CPU time) and not including only ctranslate2, but my whole process of tokenization.
I thought some people might appreciate the info… so here is what I got:
Beam size
Based on Bleu Score (highest the better):
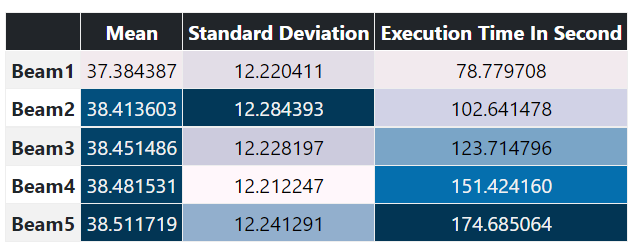
Based on WER Score (lowest the better):
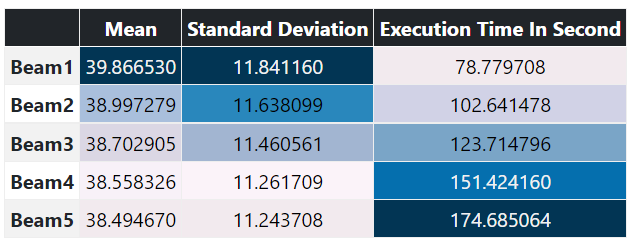
Based on METEOR Score (highest the better):
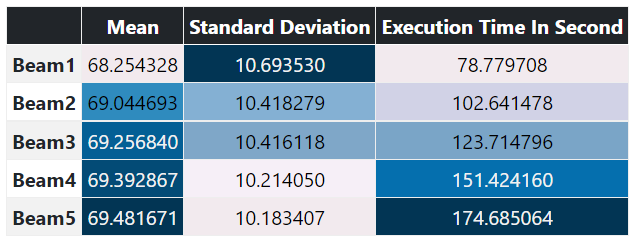
Based on hLEPOR (highest the better):
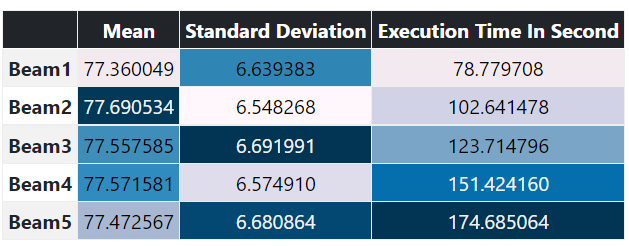
Conclusion: If run time is an issue for you, but you care to get some gain, go for beam size = 2. If runtime is not an issue, put the highest you can (should be the beam_width used during your model training)
I’m personally using Beam size = 2 for batch translation and beam size = 15 when it’s a single sentence to give many suggestions.
Repetition Penality:
Based on Bleu Score (highest the better):

Based on WER Score (lowest the better):

Based on METEOR Score (highest the better):

Based on hLEPOR (highest the better):

This is a tricky one as if you increase the repetition penalty you effectively get much less repetition, but it also has a tendency to make the sentence shorter as well. Which mean that the translation might look less like your “style”. For example, instead of “He is there.” the machine would have chosen “He’s there.” even if “He is there.” was technically more frequent in your training data.
The other thing to take into consideration is that BLEU score isn’t the best score to compare that metric since when it’s a repetition the 1 gram won’t be impacted and thus generating less “differences” on the BLEU score. The WER score is a better reference.
I’m personally using only 1.02.
Length Penality:
Based on Bleu Score (highest the better):

Based on WER Score (lowest the better):

Based on METEOR Score (highest the better):

Based on hLEPOR (highest the better):

So this parameters is tricky in the sense that it should only be used if you have a reason to force translation to be shorter or longer. The model will learn the style of your data. So the only reason I can think of to use this parameter is if you’re using external data that has longer or shorter sentences?
In my case i’m not using external data so that is why 0 is clearly the winner.
I’m personally leaving it at 0.
Hope this help someone!
Best regards,
Samuel