I m generating a translation model between Arabizi (arabic dialecte written in latin script ) and arabic . the probleme is that i am getting a blue score of 0.0 . i don’t know if OpenNMT support arabic lenguage or not !! please could someone help.
Hello , i have a dataset of 3000 sentence , i am using the quistart : here it the configuration i am using
for preprocessing :
th preprocess.lua -train_src data/src-train.tok -train_tgt data/tgt-train.tok -valid_src data/src-val.tok -valid_tgt data/tgt-val.tok -save_data data/demo
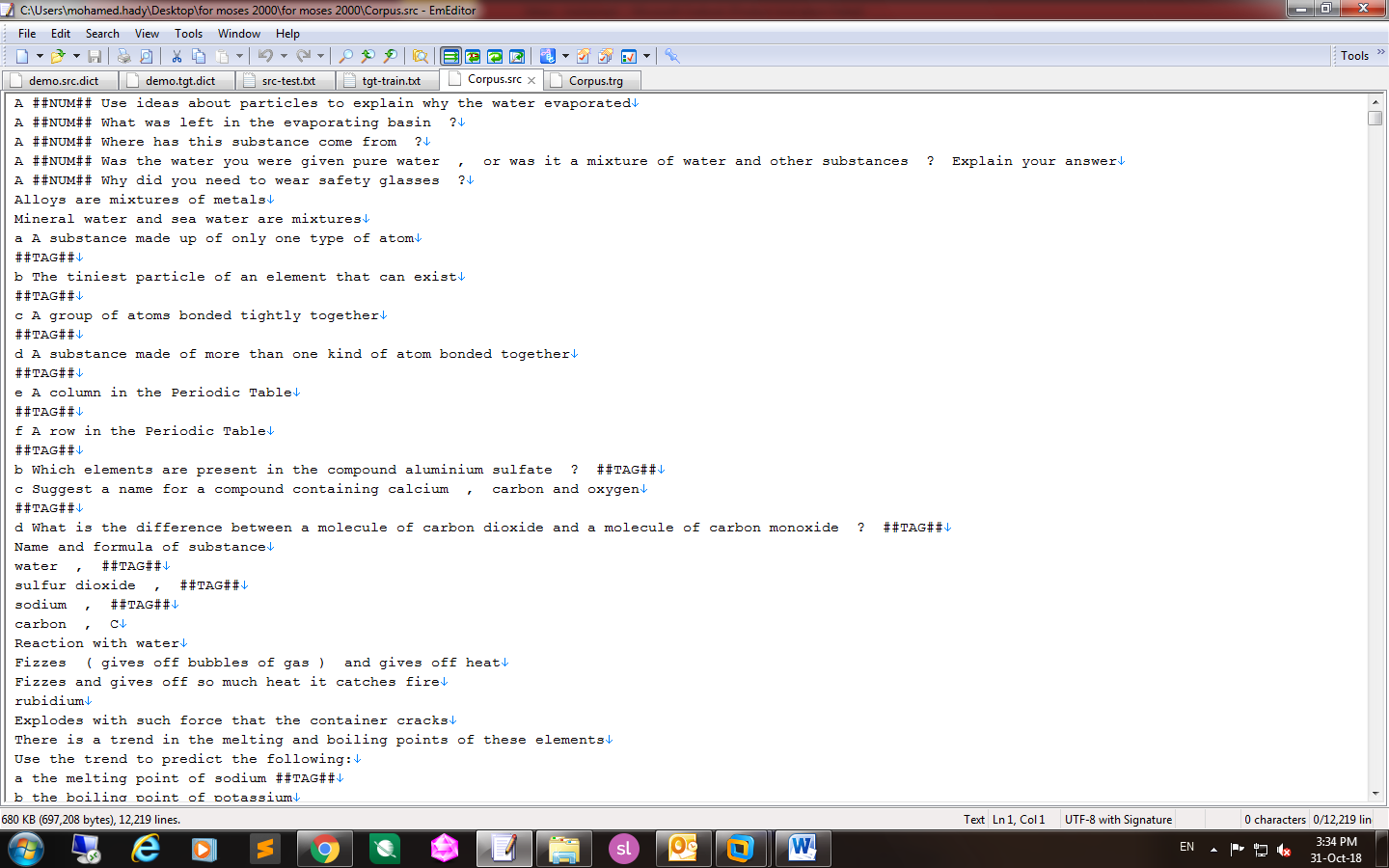
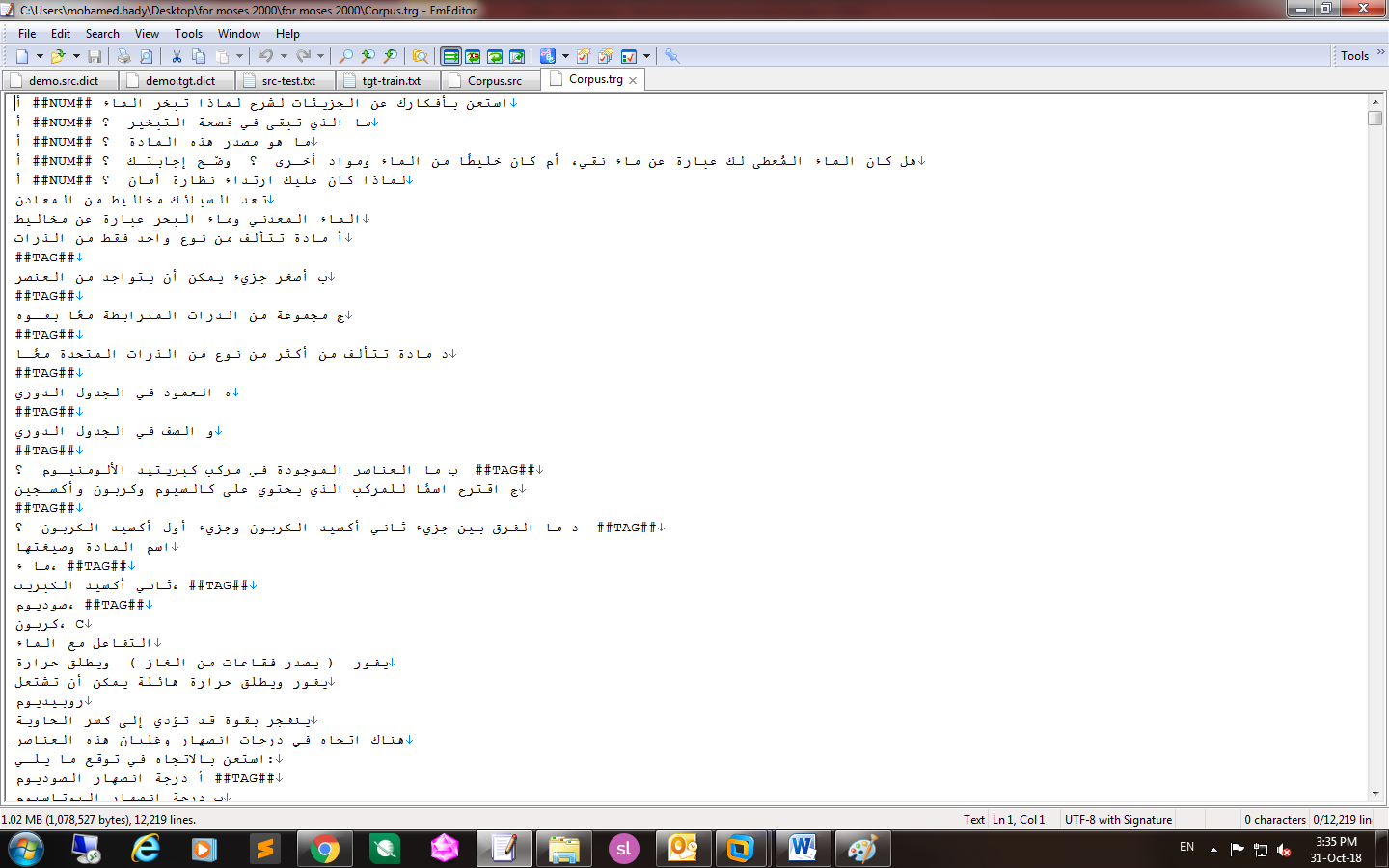
Hello everyone, I start to use OpenNMT to translate English-to-Arabic datasets but results were so bad and pred-scores were always negative, so please could you help me to know the best ways to prepare the corpus before start to processes and train the MT or understand the way OpenNMT use while processes and train using Arabic corpus.
It’s about 14219 sentences
first I Remove Invalid Characters
then Remove Redundancy
then I start to clear the files through :
1- I put spaces before and after words that have the special character ‘&’, whether the character has a space after it or not.
2- Replace full stops/periods at the end of each line with space + full stop/period, remove Not Used words (i.e. identical lines) and remove the space created previously (trims the two lines) before words that have ‘&‘ character.
3- Replaces numbers with ##NUM##.
4- Puts spaces around numbers and removes redundant spaces
5- Puts spaces around foreign sequences/ “not-target” characters found in the target file
6- Remove the unwanted spaces before/after a sentence
7- Insert spaces before and after some Predefined special characters
8- Remove the unwanted spaces before/after a sentence
Then after cleaning I start to generate a suggested abbreviation lists for both source and target files in the corpus. According to ONE criterion.The two output files are then revised by linguists.
Then I start segmentation (Convert Lines into Segments ) by converting paragraphs into segments through :
1- Remove the dot in the end of a paragraph/line.
2- Generates lots of empty line
Then I Filter Segments (not sentences) by :
1- Remove empty lines.
2- Put spaces between special characters if they are in the middle of the sentence, or put a space
after it if the special character starts the sentence.
Then I clean the test set (put a white space before a full stop, remove the unwanted spaces in any sentence and in the whole file and put white spaces before and after the special characters like ‘!’) and replace number with the tag ##NUM## reserving the index of each number in the file.
Hey @guillaumekln, Is that possible to get a good result with the help of pre-trained vectors? Like 10,000 sentence pairs with fasttext pre-trained embeddings.