I am training a 2-layer LSTM seq2seq model (en to en) with a character level encoder and a word level decoder with pertained embeddings.
I am working with ~1million lines of data which I am training for 200k steps with Adam optimiser(0.001).
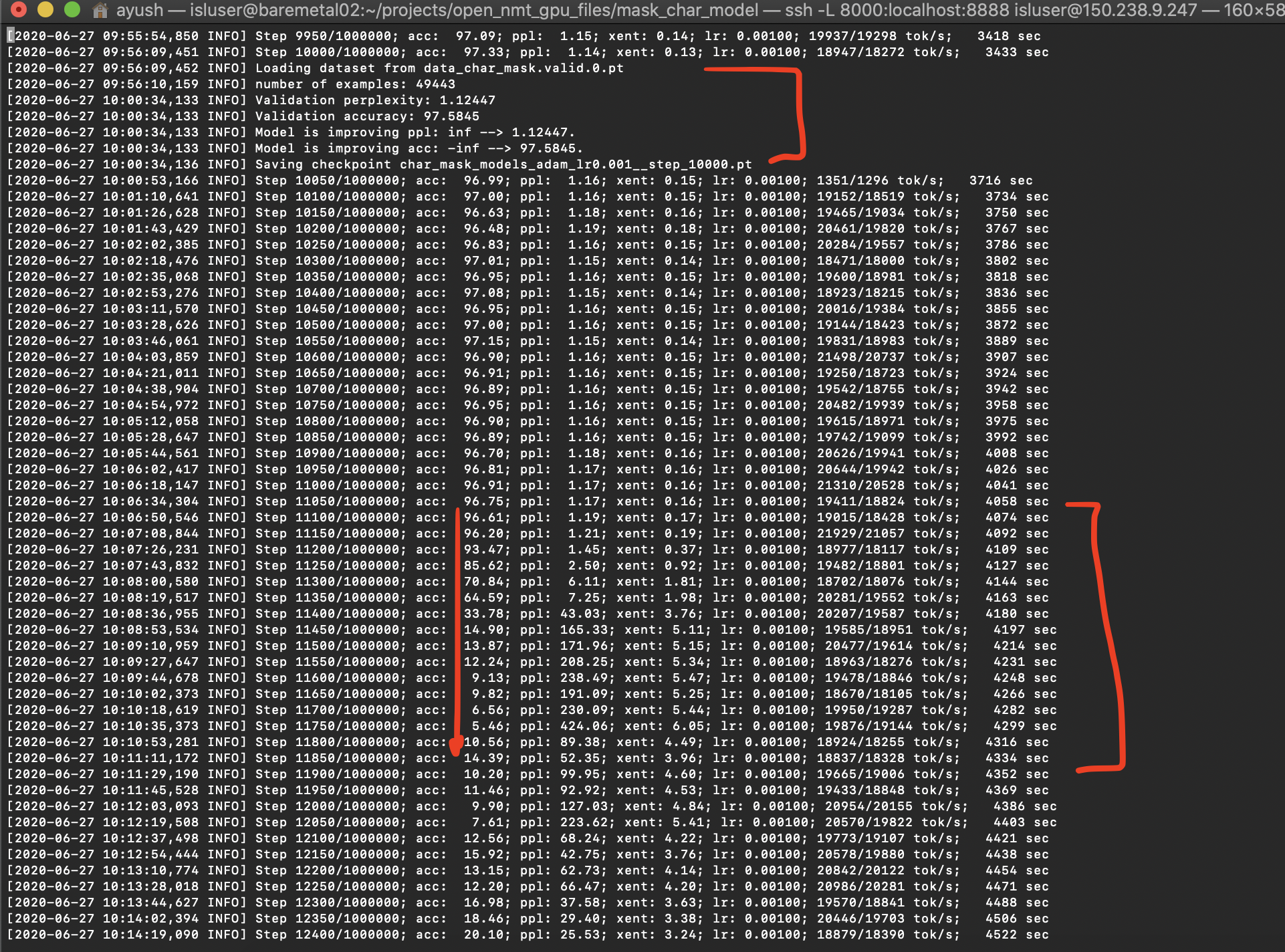
The training starts off pretty well and goes upto 92% accuracy; ppl 1.2; xent: 0.2 at around 10000/200000 and stays in its vicinity till 21000th step. At this point the log shows another load from train data post which the accuracy gradually declines to a mere 25% and stays around the same value.
I have validation runs at every 5000 steps and the validation scores for 5000th and 10000th steps were both around 90% with ppl:1.< > and xent lower than 0.5. which also came down to low 20s after 21k steps.
Can anyone give me an insight into what might be happening? I was wondering if it was because my data is not shuffled, but the validation runs should have come back with a miserable score in that case as it contains around 50k sentences of all sizes.
Edit: I ran translate on the later checkpoint to find out that the model was repeatedly printing the same 10 tokens for all inputs. Can anyone help me understand why that started happening suddenly?
Hi @guillaumekln. The dataset was shuffled before creating the training text files. Here are the steps I took. This is for a character-level model now. Where instead of a word level decoder, I have hooked in a character-level one.
In the attached log file, you can see that validation ppl and accuracy are also in similar range and then after a few steps the perplexity starts increasing.
I am using Adam optimiser with an lr of 0.001.
PS. The validation dataset is a balanced representation of all kinds of data used to make the corpus.
Also, is this normal functionality? I have just one shard of data but there are subsequent loads from the pt file. ( the batch size is 64, so 7.5k steps are not enough to have one epoch over the entire ~1mil lines to have a reload) Moreover there is a step between load dataset INFO and number of example INFO.
This behaviour is quite strange, not sure where it could come from.
As for the “early reloading” of your data it’s because of the pooling mechanism we use to rationalize the dataloading pipeline.
Basically, instead of just taking one batch at a time, we read batch_size * pool_factor examples (pool_factor defaults to 8192), order these by length (to have homogeneous batches), create batches, shuffle these and yield them to the GPUs.
hi @francoishernandez
I tried reshuffling my data as well as changed the split ( to include more validation datapoints). But even after the shuffle, I encountered the same behaviour.
It happens when I keep my lr ~0.01 for Adam and (1-0.1) for sgd. A smaller lr, like 1e-4 for Adam doesn’t result in this scenario.
But I cannot figure out what can be going wrong with it theoretically. Because if the lr is too big to locate such a saddle point, it should fluctuate and not stagnate. Also, I don’t see how (even if there are such points) a small set of difficult/peculiar sentence can throw my model so off track that further training cannot improve it, even when the losses incurred are huge!?
Is there something I’m doing wrong while calling the preprocessing or train files?
It worked fine with your advised lr range and the model converged.
Thanks for the help!
However I am still not able to make out what might be going wrong with a seq2seq LSTM model with standard learning rates ( 0.01 for Adam and 1 for sgd)