Can i log something like confident score for translate. I want to check if confident score is lower than 50% i will call my api to translate instead
When you say “confident score” you are referring to “prediction score”?
I really dont know. but prediction score is base on tgt.txt right? But confident score is the score how many percent model think that sentences have predicted was right and it not base on tgt.txt. I think so @SamuelLacombe
I believe “confident score” is the equivalent of “predict score” in Opennmt… i don’t know where you read about that, but I’m pretty sure it’s the equivalent or a derivate from the “predict score”.
here is some doc about predict score… and they mention this:
Most common ML confidence scores
There is no standard definition of the term “confidence score” and you can find many different flavors of it depending on the technology you’re using. But in general, it’s an ordered set of values that you can easily compare to one another.
You can achieve your goal with the “predict score”. First, you would need to determine the BLEU score or what ever score you want to use to evaluate your test set (from Opennmt model and your other model). And then, make sure to have the “predict score” for each “segments” that is in your test set. Round it up to the nearest integer, and find the sweet spot.
In the example below… the sweet spot would be somewhere between -5 and -3 (if i exclude google automl)… Anything above that sweet spot is most likely better than the model you would compare
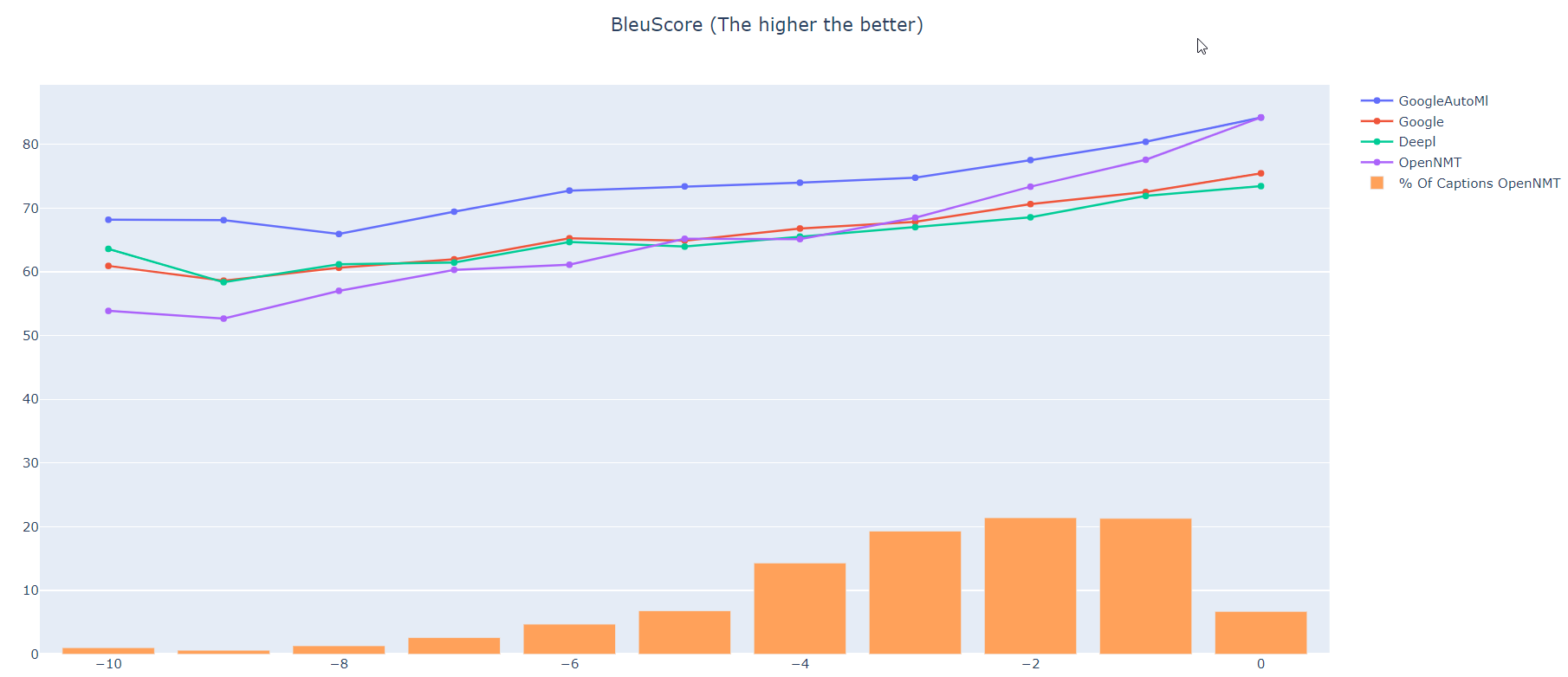
You might want to use the sentence length as it has an impact on the predict score… but was not really relevant in my case so I didn’t.
yeah thanks a lot thats really helpful . And one more thing about Predict score is it the lower the better ? i really confuse about it because some sentence seem less unknow word in translate but predict score is really high ~ -89. And Is unknow word has impact to my predict score too?
the closer to 0 the better. The negative sign is important here… so -89 is worse than -2. As for unknow word… I don’t know.
After some thoughts, I would recommend to try to create a model with opennmt-tf and use the n_best >1 in the infer section. Then compare when there is only a difference between the suggested translation for the same segment… it might give you a hint on how it can impact. I remember seeing sometimes cases where the second option was actually better than the first one. Yet, the first one was 1 word replaced by .
Yeah thanks ,i understand now. And how can i compare predict score with my number like 50. I see it only log on the console. i really want to have it in my predict.txt
Once your model is generated, through command line use infer and add the parameter:
–predictions_file “yourFilePath.yourfilename.txt”
This will get the translation + predict score in one file.
If you want to create something more automated (with an exported model)
See in the instruction how to used saved_model in python and see this topic:
Predict score with saved_model