I have Two pretrained Embedding … one for encoder and other for decoder. how can I make it into OpenNMT?
Can you check if the documentation helps?
http://opennmt.net/OpenNMT-py/FAQ.html#how-do-i-use-pretrained-embeddings-e-g-glove
OK, but I have two text files for embeddings called
my_ast_emb.txt and my_com_emb.txt as glove format
http://opennmt.net/OpenNMT-py/FAQ.html#how-do-i-use-pretrained-embeddings-e-g-glove
this method generate embeddings.enc.pt and embeddings.dec.pt for given only one file embedding (glove)
if I apply this method , it will be generate 4 files … two for encoder and two for decoder
so, Can I apply another method that give it two embedding and generate two files one for encoder and other for decoder?
The script has separate options for source and target: -emb_file_enc and -emb_file_dec
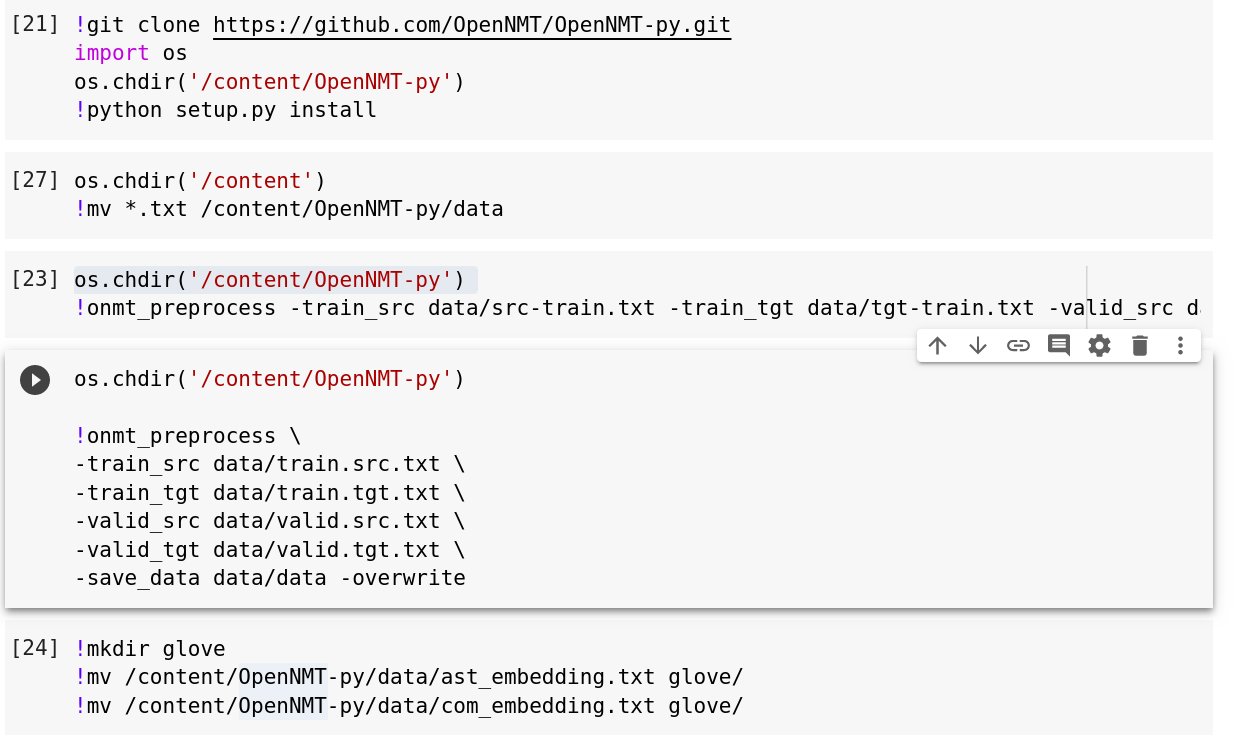
woow Good I understand, for clarification, I split my data ( train-test-valid)
this command
onmt_preprocess -train_src data/train.src.txt -train_tgt data/train.tgt.txt -valid_src data/valid.src.txt -valid_tgt data/valid.tgt.txt -save_data data/data
does not include test data because my embeddings include all data
is it cause any errors?

Try with Python 3.
Thank you, sir
I ran the command, and there is an error
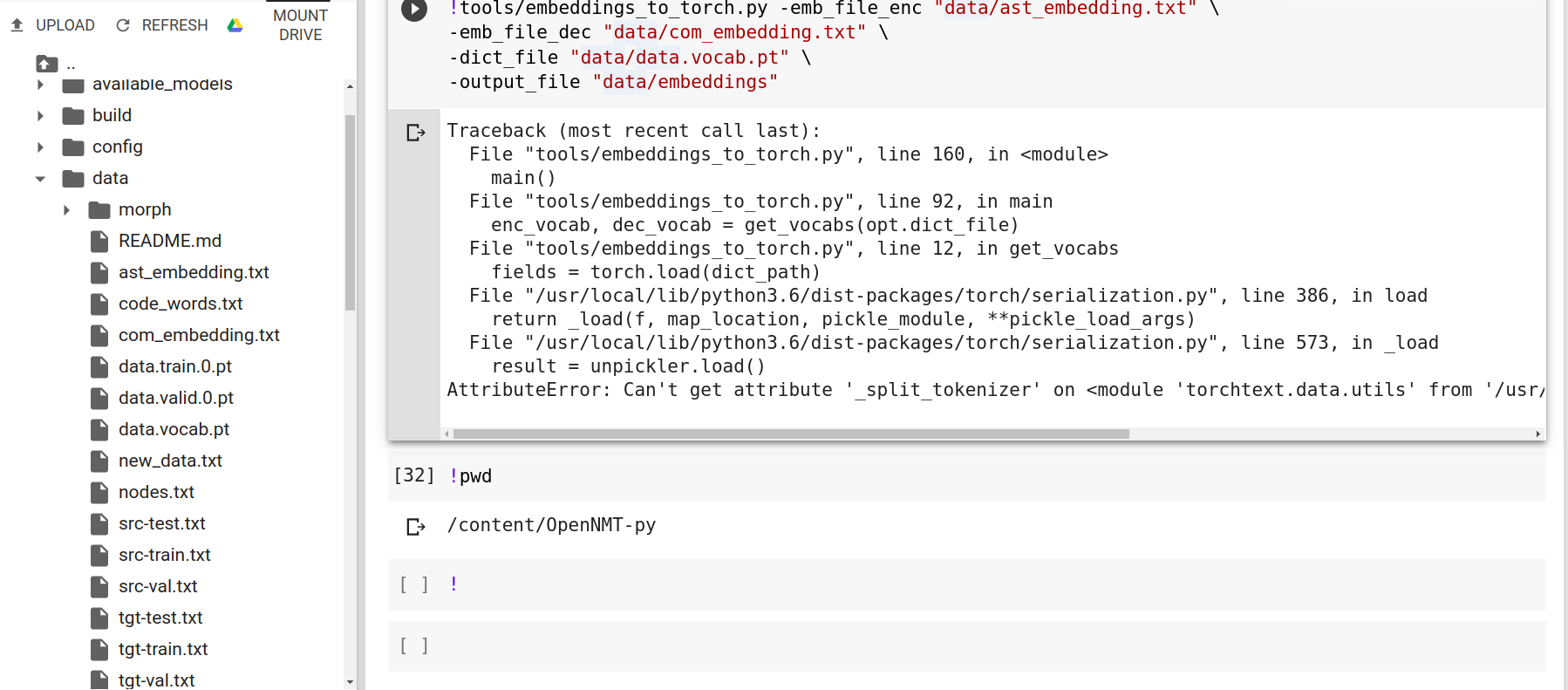
The full description :
AttributeError: Can’t get attribute ‘_split_tokenizer’ on <module ‘torchtext.data.utils’ from ‘/usr/local/lib/python3.6/dist-packages/torchtext/data/utils.py’>
This Error appear when I ran this method that found here:
http://opennmt.net/OpenNMT-py/FAQ.html#how-do-i-use-pretrained-embeddings-e-g-glove
See the OpenNMT-py installation instructions:
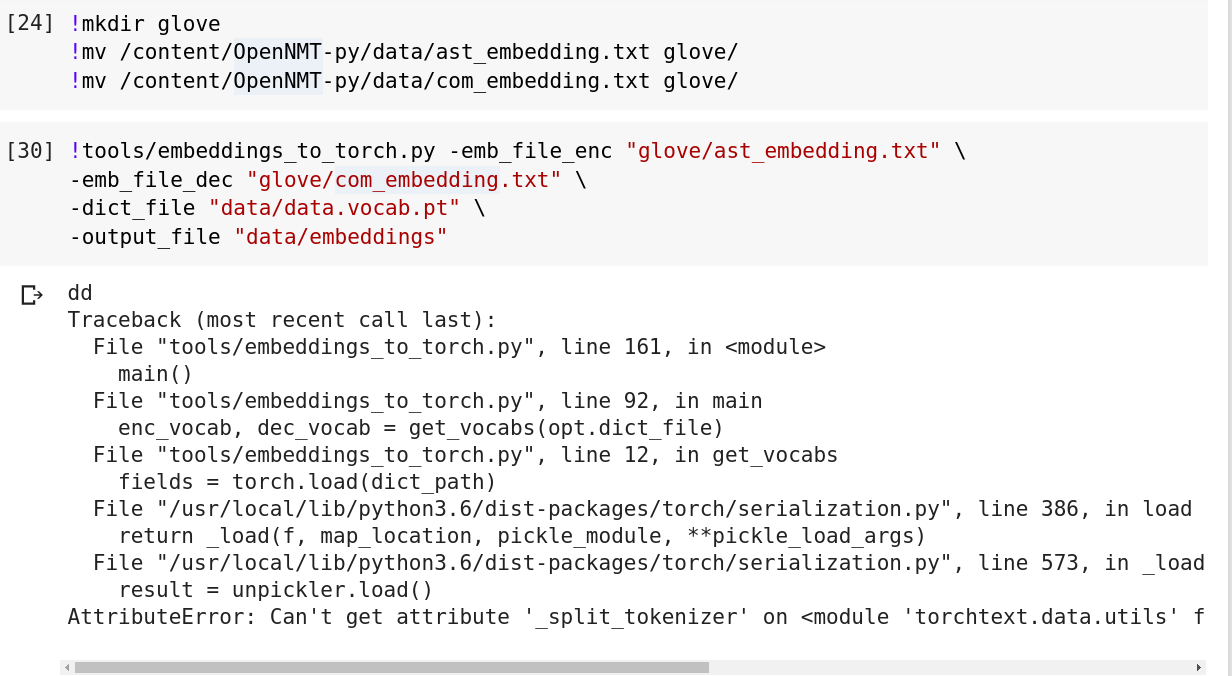
Can you verify that torchtext 0.4.0 is correctly installed? It is the version required by OpenNMT-py.
wooow well sir, many thanks sir