This tutorial describes how to perform monophone speech recognition with OpenNMT Sequence Tagger.
#1. Data preparation
OpenNMT needs source and target for training. For the monophone speech recognition, source is a sequence of acoustic feature and target is a sequence of monophone speech. Here we make use of TIMIT corpus where monophones are annotated with timestamp of audio file. The following Github repository helps to build source and target using Kaldi speech recognition toolkit.
#2. Lua 5.2 installation
A sequence of acoustic feature is quite heavy to be running completely. Lua 5.2 helps to load such large data in OpenNMT. LuaJIT user will need to limit the length of source and target sequences. You can install Lua 5.2 as shown in the following.
git clone https://github.com/torch/distro.git ~/torch --recursive
cd torch
TORCH_LUA_VERSION=LUA52 ./install.sh
#3. Running OpenNMT
th preprocess.lua -data_type 'feattext' \
-train_src train.fbank120.clean \
-train_tgt train.tgt.clean \
-valid_src dev.fbank120.clean \
-valid_tgt dev.tgt.clean \
-save_data TIMIT_clean_800 -check_plength false \
-idx_files -src_seq_length 800 -tgt_seq_length 800
CUDA_VISIBLE_DEVICES=0 \
th train.lua -data TIMIT_clean_800-train.t7 \
-save_model asr_timit_clean_800_seqtagger_brnn_sgd029 \
-brnn -report_every 1 -rnn_size 512 -word_vec_size 65 \
-model_type seqtagger -layers 3 -max_batch_size 8 \
-learning_rate 0.29 -dropout 0 -learning_rate_decay 1 \
-end_epoch 30 -gpuid 1
CUDA_VISIBLE_DEVICES=0 \
th tag.lua -src test.fbank120.clean \
-model asr_timit_clean_800_seqtagger_dbrnn_sgd029_epoch10_2.74.t7 \
-idx_files true -batch_size 1 -gpuid 1
/home/kwon/TIMIT3/asr_timit_clean_800_seqtagger_brnn_sgd029_epoch10_2.70.t7'...
[06/14/17 21:59:44 INFO] FEATS 1: IDX - mjdh0_si1984_dr6 - SIZE 131
[06/14/17 21:59:44 INFO] PRED 1: h# h# h# h# h# h# h# h# h# h# h# h# h# q dh ih ih ih ih m m m w w w w w w w ah ah ah ah ah ah ah dx dx dx ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay s s z z z s s s th th dh dh dh dh ey ey ey ey ey ey ey w w w w w w w w w w w w w w ao er er er er er er er er er er er axr axr axr axr axr h# h# h# h# h# h# h# h# h# h# h# h# h# h# h# h# h# h#
[06/14/17 21:59:44 INFO]
[06/14/17 21:59:44 INFO] FEATS 2: IDX - mjdh0_si1984_dr6 - SIZE 145
[06/14/17 21:59:44 INFO] PRED 2: h# h# h# h# h# h# h# h# h# h# h# y y y y y y y hv uw uw uw ow ow ow ow ow ow ow ow ow ow ow q q q q q q q q iy iy iy iy iy iy iy iy iy iy dcl dx dx ih ih ih ih ix ix ix n n n n n ah ah ah ah ah ah ah ah ah ah ah ah ah ah f f f f f f f f f f f pau pau pau pau pau hh hh hh hh hh hh hh hh hh hh hh ah ah ah ah ah ah ah ah ah n n nx n iy iy iy iy iy iy iy iy iy iy h# h# h# h# h# h# h# h# h# h# h# h# h# h# h#
[06/14/17 21:59:44 INFO]
[06/14/17 21:59:44 INFO] FEATS 3: IDX - mjdh0_si1984_dr6 - SIZE 158
[06/14/17 21:59:44 INFO] PRED 3: h# h# h# h# h# h# h# h# h# h# h# h# h# sh sh sh sh sh sh sh sh sh sh sh sh sh sh sh iy iy iy iy iy iy iy iy iy iy iy iy ih ih ih ih ih s s s s s s s s s s tcl tcl tcl t t t t t ih eh eh eh eh eh eh eh nx n n er er axr axr axr axr axr axr er er er er er dh dh dh dh dh ix ix ix ix ix ix ix ix n n n n n ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ay ae ae ae ae ae ae ae ae ae ae ae ae ae ae ae ae ux ux m h# h# h# h# h# h# h# h# h# h# h# h#
[06/14/17 21:59:44 INFO]
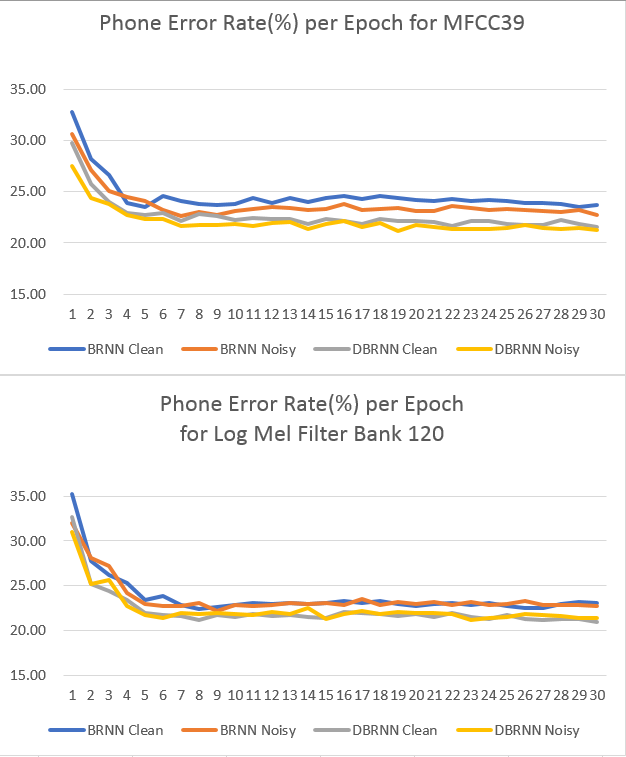
#4. Results
For PER(Phone Error Rate) calculation, you need to consider a group of phones. You will be able to try different options and parameters for the training.