where t contains prefix (seed) of sentences - can be empty. Random sentences up to L words will be generated. The parameter T between 0-1 governs how random should be the generation. The closest to zero, the more consistent and less random.
Any feedback is welcome, and as a teaser, I trained a LM on the corpus from:
and the LM can generate random questions that the chatbot will answer ! Just for the fun a sample:
LM@Bot: Where is my love?
Bot@LM: Tell me.
LM@Bot: Has Ken come back yet?
Bot@LM: no, not yet
LM@Bot: WHATS HITCHKOK EXACTLY?
Bot@LM: I DON'T KNOW.
LM@Bot: Where do you put eyes on your bitter sack then walsh?
Bot@LM: I don't.
LM@Bot: Did you and Rosemary know each other?
Bot@LM: Yes.
LM@Bot: Can I be of some assistance?
Bot@LM: no, I'm fine.
LM@Bot: who's slow?
Bot@LM: I'm slow.
LM@Bot: what the hell did dave want?
Bot@LM: I don't know.
LM@Bot: Did she say I needed money?
Bot@LM: yeah.
LM@Bot: what the hell have you been up to?
Bot@LM: Nothing.
LM@Bot: Hey, anybody home?
Bot@LM: Hey.
LM@Bot: Where have Magi lived?
Bot@LM: I'll tell you.
would be great to add Importance sampling or NCE, because for very large vocabulary, it is rather infeasible right now on large corpus. see for instance the Google billion word corpus.
Jean,
great will do.
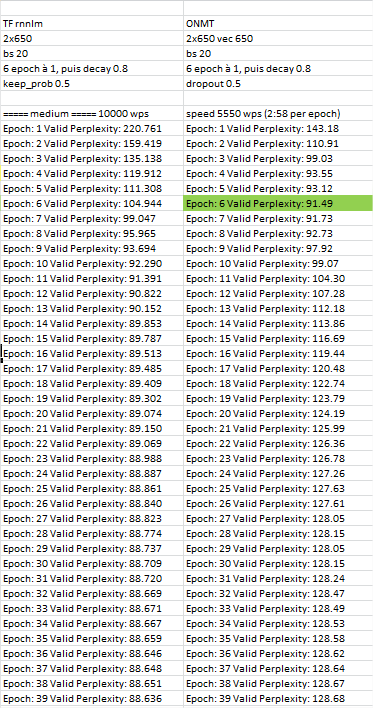
However, on a smaller corpus (where sampling is less critical) given my first results, I have the feeling that we may need variational dropout as opposed to the regular one.
PPL decrease quite quickly but re-increase quite significantly. Tested on PTB.
Hi Vincent, no - there is no attention layer in the LM (or the seqtagger).
The reason is that the attention model is part of the decoder, it could be possible to introduce a variant of attention though between encoder and generator.
Hello @Crista23 - no there is none, but this can be added easily: we just need to ignore ‘’ token generation for at least this length number of steps. Let me know if you want to have a try and submit a PR or I can do it.
Is there a way to quickly get scores from the LM for partial hypotheses? I would like to use the LM in a NLG-system and use it for pruning generation hypotheses.
thans for the report on -mode, there is actually a discrepancy between doc and cli, I will fix. I just added here a patch so that ‘-’ stands for STDIN - to be used for lm.lua (or translate, tag)
Thanks, that works nicely.
But when I run th lm.lua score -model /home/knox/nlm/dutchnlm_epoch3_44.03_release.t7 -src testje.txt
several times, I get different scores each time
This also happens when I use STDIN as input method
How did you manage to create the models? I can’t make training work at all. I use
cd /OpenNMT
for f in "${src_train}" "${src_val}"; do th tools/tokenize.lua -segment_numbers < "${f}" > "${f}.tok";done
th preprocess.lua -data_type monotext -train "${src_train}.tok" -valid "${src_val}.tok" -save_data "${fldr}/models/${prefix}"
th train.lua -model_type lm -data ${fldr}/models/${prefix}-train.t7 -save_model ${fldr}/models/${prefix} -gpuid 1
and I get
[05/18/18 12:49:32 INFO] Preallocating memory
/torch/install/bin/luajit: ./onmt/train/Trainer.lua:156: attempt to get length of field 'targetInputFeatures' (a nil value)
stack traceback:
./onmt/train/Trainer.lua:156: in function '__init'
/torch/install/share/lua/5.1/torch/init.lua:91: in function 'new'
train.lua:332: in function 'main'
train.lua:338: in main chunk
[C]: in function 'dofile'
/torch/install/lib/luarocks/rocks/trepl/scm-1/bin/th:150: in main chunk
[C]: at 0x00405d50
I am using the latest ONMT code (just ran git pull origin master when inside the ONMT folder).
I’ve been trying to understand the scores output by lm.lua, and it appears that the score output is actually the loss of the model (https://github.com/OpenNMT/OpenNMT/blob/master/onmt/lm/LM.lua#L142), which is the log of the perplexity. Am I missing something, or is it indeed the log of the perplexity?
Hello! I can see this issue is close but I’m still having the same problem when training the LM
/root/torch/bin/luajit: ./onmt/train/Trainer.lua:156: attempt to get length of field 'targetInputFeatures' (a nil value)
stack traceback:
./onmt/train/Trainer.lua:156: in function '__init'
/root/torch/share/lua/5.1/torch/init.lua:91: in function 'new'
train.lua:332: in function 'main'
train.lua:338: in main chunk
[C]: in function 'dofile'
/root/torch/lib/luarocks/rocks/trepl/scm-1/bin/th:150: in main chunk
[C]: at 0x00405d50
Please note that language model training, scoring, and sampling are all implemented in OpenNMT-tf (but not LM fusion with seq2seq). You will be get better support there as OpenNMT-lua is now deprecated.
 ! Just for the fun a sample:
! Just for the fun a sample: