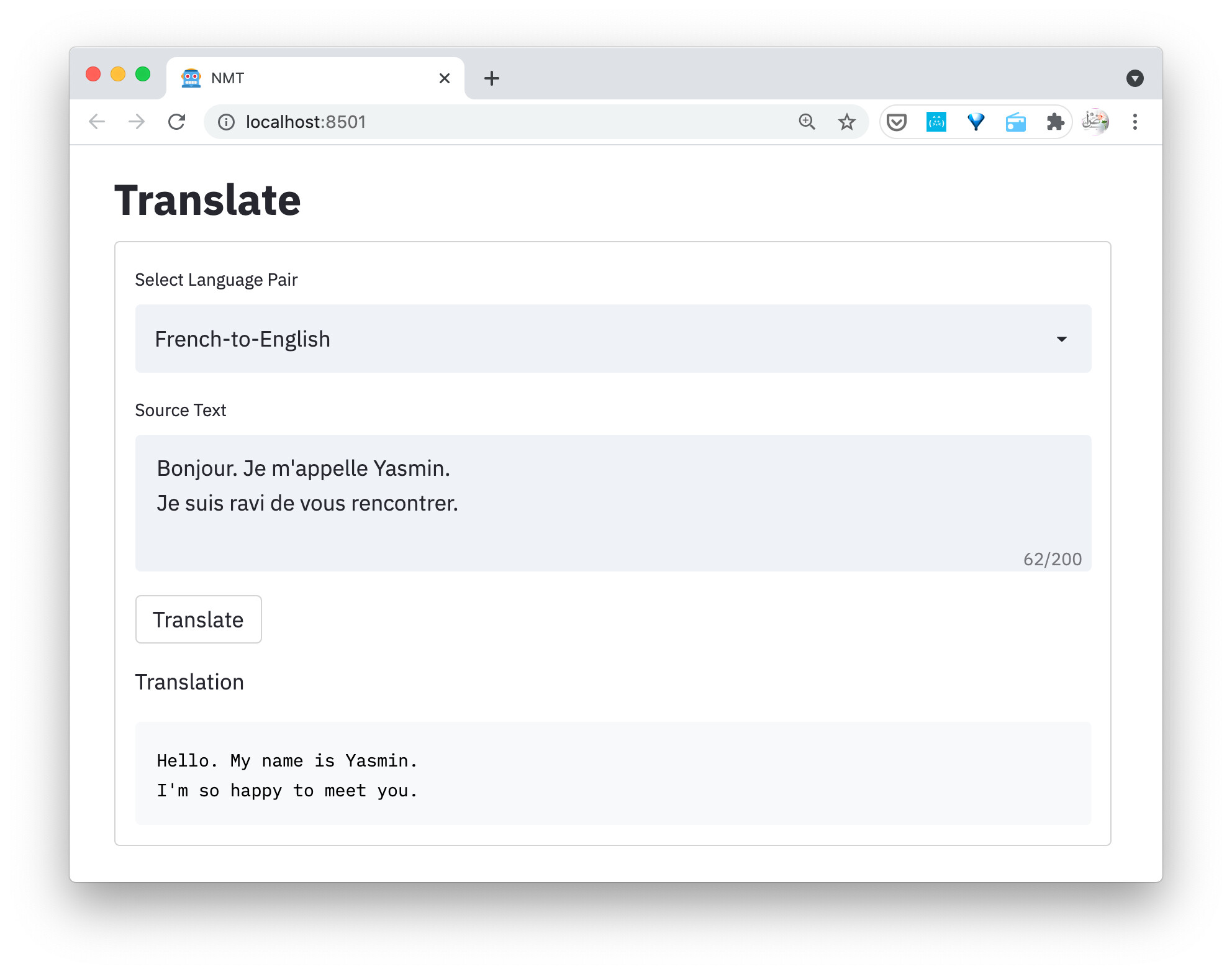
I have two sentences which are being input to my translation interface. The two sentences are separated by one or more than one new line characters. Example -
Sentence 1. Sentence 2.
The translated sentence gets converted to Translation of Sentence 1. Translation of Sentence 2.
What would be the best way to preserve the information about the new line characters so that the translated output instead is -
Translation of Sentence 1. Translation of Sentence 2.
It is quite likely that you lose those new line characters during normalisation or tokenisation. One way to preserve that information would be to protect the new lines with a special token in the target segments when preprocessing data for training and inference, then restoring the new lines when denormalising/detokenasing. This is what I did for non-breaking spaces, and it worked well.
Daniel’s solution is perfect, and I am happy that he shared it.
The way I am achieving this with CTranslate2 is that I split the input text on new lines, split sentences in each line, and then pass one list of sentences to CTranslate2 at a time. Maybe this is not the best method, but you now got the idea.
Hi Anurag, I can confirm Yasmin’s solution. You can, of course, do the splitting of paragraphs into one line per sentence in a pre-processing stage. The NLTK toolkit has scripts for this. Terence