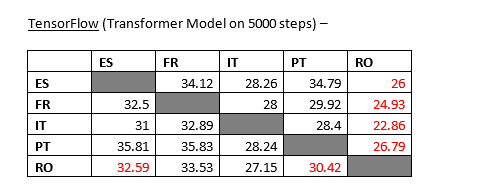
I will post a commit on this recipe because I used a detokenized bleu score vs the tuto above where scores are calculated on tokenized output.
Doing the calculation on tokenized output I get about the same scores as the tuto with a smaller network:
test-esfr_multibleu.txt:BLEU = 32.78, 61.8/41.2/29.8/22.1 (BP=0.911, ratio=0.915, hyp_len=15036, ref_len=16436)
test-esit_multibleu.txt:BLEU = 28.64, 58.2/36.5/25.1/17.8 (BP=0.918, ratio=0.921, hyp_len=13906, ref_len=15091)
test-espt_multibleu.txt:BLEU = 34.52, 64.5/43.2/31.5/23.5 (BP=0.911, ratio=0.914, hyp_len=13004, ref_len=14221)
test-esro_multibleu.txt:BLEU = 27.21, 57.2/34.9/23.9/16.8 (BP=0.909, ratio=0.913, hyp_len=13279, ref_len=14550)
test-fres_multibleu.txt:BLEU = 32.09, 62.8/40.8/28.8/20.7 (BP=0.912, ratio=0.916, hyp_len=13762, ref_len=15027)
test-frit_multibleu.txt:BLEU = 27.34, 57.3/35.3/24.0/16.6 (BP=0.912, ratio=0.916, hyp_len=13509, ref_len=14751)
test-frpt_multibleu.txt:BLEU = 30.27, 61.1/38.6/26.9/19.0 (BP=0.915, ratio=0.918, hyp_len=13148, ref_len=14323)
test-frro_multibleu.txt:BLEU = 25.40, 55.1/32.5/21.6/14.9 (BP=0.922, ratio=0.924, hyp_len=13116, ref_len=14188)
test-ites_multibleu.txt:BLEU = 30.11, 61.6/39.2/27.3/19.4 (BP=0.896, ratio=0.901, hyp_len=13241, ref_len=14698)
test-itfr_multibleu.txt:BLEU = 31.57, 60.5/39.7/28.9/21.5 (BP=0.902, ratio=0.907, hyp_len=14686, ref_len=16193)
test-itpt_multibleu.txt:BLEU = 28.02, 60.2/36.9/24.8/17.0 (BP=0.900, ratio=0.905, hyp_len=13700, ref_len=15137)
test-itro_multibleu.txt:BLEU = 23.82, 53.8/31.2/20.7/14.0 (BP=0.903, ratio=0.907, hyp_len=13265, ref_len=14623)
test-ptes_multibleu.txt:BLEU = 35.34, 65.3/43.7/31.7/23.2 (BP=0.928, ratio=0.931, hyp_len=13751, ref_len=14772)
test-ptfr_multibleu.txt:BLEU = 34.03, 63.3/42.8/31.6/23.8 (BP=0.900, ratio=0.905, hyp_len=14882, ref_len=16451)
test-ptit_multibleu.txt:BLEU = 28.18, 57.2/35.8/24.6/17.2 (BP=0.924, ratio=0.927, hyp_len=13547, ref_len=14618)
test-ptro_multibleu.txt:BLEU = 28.54, 57.8/36.1/24.8/17.3 (BP=0.927, ratio=0.930, hyp_len=13536, ref_len=14561)
test-roes_multibleu.txt:BLEU = 32.67, 63.8/41.6/29.6/21.4 (BP=0.907, ratio=0.911, hyp_len=13592, ref_len=14914)
test-rofr_multibleu.txt:BLEU = 33.01, 61.6/41.1/30.0/22.3 (BP=0.916, ratio=0.919, hyp_len=15274, ref_len=16622)
test-roit_multibleu.txt:BLEU = 26.97, 56.5/35.0/23.9/16.9 (BP=0.902, ratio=0.907, hyp_len=13590, ref_len=14986)
test-ropt_multibleu.txt:BLEU = 30.33, 61.7/39.1/27.0/18.9 (BP=0.911, ratio=0.914, hyp_len=13790, ref_len=15082)