Is there a way to remove this time shifting, in order to produce the output like a single multiplexed stream ?
Yes, if you accept to change a bit the code:
diff --git a/onmt/translate/DecoderAdvancer.lua b/onmt/translate/DecoderAdvancer.lua
index ecf8dc7..46ee81c 100644
--- a/onmt/translate/DecoderAdvancer.lua
+++ b/onmt/translate/DecoderAdvancer.lua
@@ -41,7 +41,7 @@ function DecoderAdvancer:initBeam()
local features = {}
if self.dicts then
for j = 1, #self.dicts.tgt.features do
- features[j] = torch.IntTensor(self.batch.size):fill(onmt.Constants.EOS)
+ features[j] = torch.IntTensor(self.batch.size):fill(onmt.Constants.BOS)
end
end
local sourceSizes = onmt.utils.Cuda.convert(self.batch.sourceSize)
diff --git a/onmt/translate/Translator.lua b/onmt/translate/Translator.lua
index 05170e0..ec8a777 100644
--- a/onmt/translate/Translator.lua
+++ b/onmt/translate/Translator.lua
@@ -149,7 +149,7 @@ function Translator:buildTargetFeatures(predFeats)
table.insert(feats, {})
end
- for i = 2, #predFeats do
+ for i = 1, #predFeats - 1 do
for j = 1, numFeatures do
table.insert(feats[j], self.dicts.tgt.features[j]:lookup(predFeats[i][j]))
end
diff --git a/onmt/utils/Features.lua b/onmt/utils/Features.lua
index b840e94..2e34108 100644
--- a/onmt/utils/Features.lua
+++ b/onmt/utils/Features.lua
@@ -96,13 +96,11 @@ local function generateTarget(dicts, tgt, cdata)
end
for j = 1, #dicts do
- -- Target features are shifted relative to the target words.
- -- Use EOS tokens as a placeholder.
table.insert(tgt[j], 1, onmt.Constants.BOS_WORD)
- table.insert(tgt[j], 1, onmt.Constants.EOS_WORD)
+ table.insert(tgt[j], onmt.Constants.EOS_WORD)
tgtId[j] = dicts[j]:convertToIdx(tgt[j], onmt.Constants.UNK_WORD)
table.remove(tgt[j], 1)
- table.remove(tgt[j], 1)
+ table.remove(tgt[j])
end
return tgtId
And as far as I can remember these are the only changes needed to have “aligned” features and words.
1 Like
Is there also a time shifting on the input side ?
No, that’s the current distinction between source and target features:
- source features: additional word information
- target features: additional word annotations
1 Like
I think the current architecture is as in this image:?
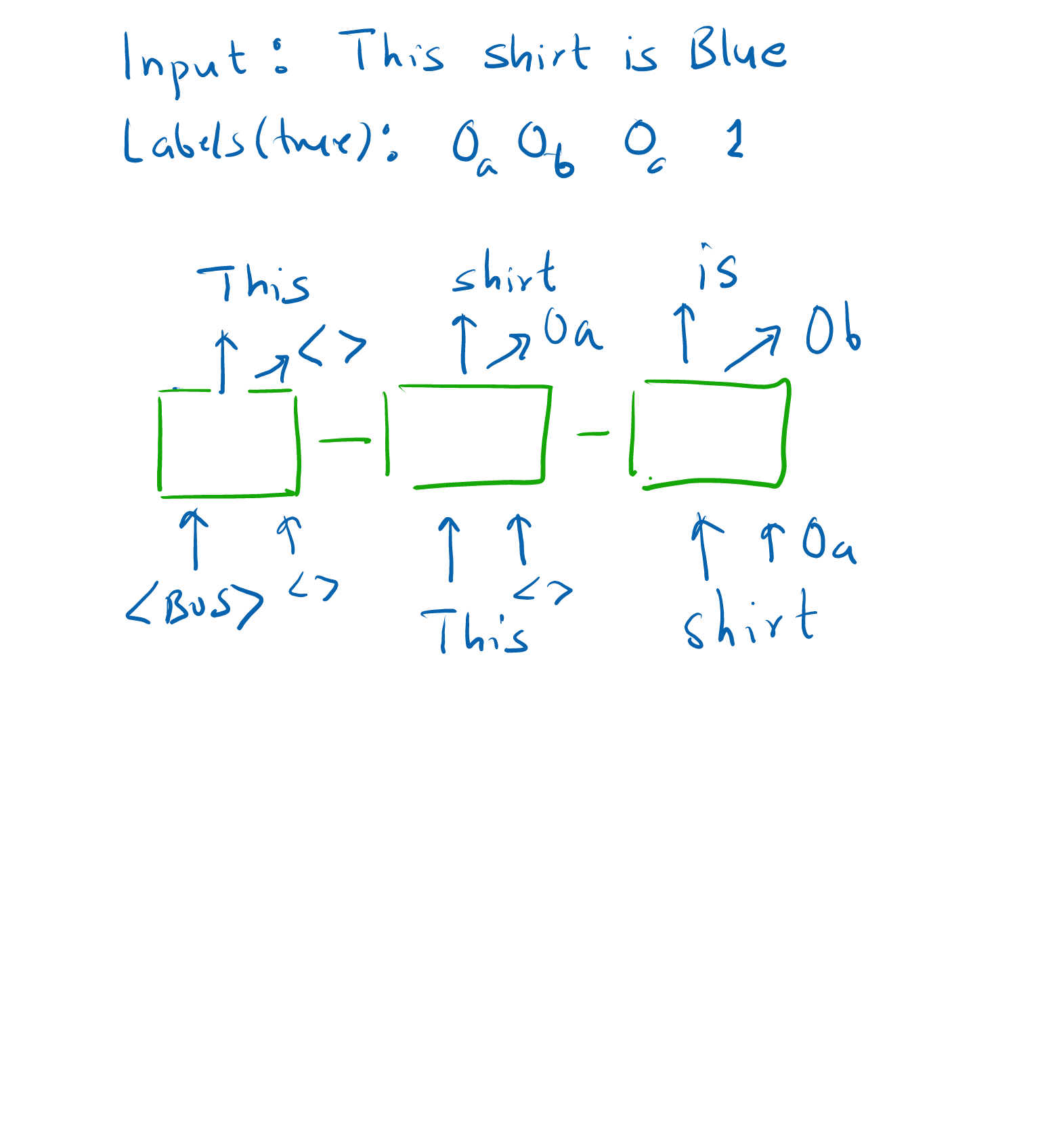
I think it makes sense to have features lagging the words (like in te current implementation) since that way the current feature can depend on the current word. @Etienne38 -what do you think?
Note: 0a, 0b etc. is just as an illustration to differentiate between the 0s
1 Like
As far as I understand, I think that your picture (decoder side only) is right.
In your very special case, as your output is a single copy of the input (full network), I would experiment without the time shifting : the information about the predicted word(t+1) is already in the input (if the attention module is working well), and, to predict it’s feature, it’s more important to provide (loop) all about the previous predicted word(t) and its feature(t), rather than having an information about this predicted word(t+1) that should be redundant with the input and mixed with feature(t)… I think, without time shifting, all the information will be more homogeneous, and delivered at the right moment.
@Etienne38 I did some quick experiments with the same hyperparameters but:
-
with words + tags on target side: Overall
94%of the tokens were correctly predicted. This is after I considered in calculation that a token predicted as<unk>is “correct”. Notagsare predicted for<unk>tokens. -
without words on the target side. Overall
99%of the tokens were correctly predicted
From this experiment atleast adding words does not seem to help for the use case. These results are on test data so not sure if the model is just memorizing the dataset. Will try training with random labels to confirm. See ICLR 2017: UNDERSTANDING DEEP LEARNING REQUIRES RETHINKING GENERALIZATION
In each part of your explanation, it’s not clear if your are speaking of the words themselves, or the tags you finally want.
What kind of ONMT configuration are you using ?
How many sentences, and total words ?
How many different words ?
How many words in the dict files ?
What size for the words embeddings and features embeddings ?
My bad. In the case of word-tag combinations as target, the metric is on the combination. The individual error rates might be much lower. Let me separately compute the accuracy for words and tags
Perhaps you may create a new specific topic in the ‘uncategorized’ category, describing as precisely as possible the conditions of your experimentation, so that we could exchange on it. All this could be a bit off-topic for this current exchange.

1 Like