I want to translate from English to Hindi but I’m facing in problem in the data prepration part in Normalisation, Tokenization part. I’m unable to use tool for same. Need help on this!
Dear Ankit,
You have at least two options:
a. use SentencePiece directly without Tokenisation, and this is an accepted approach; OR
b. use one of these tools: iNLTK, Indic NLP Library, or StanfordNLP Stanza.
This article can give you some tips.
Hope this helps.
Kind regards,
Yasmin
2 Likes
Hi Yasmin,
Thanks for your response.
I want to use OpenNLP model to train with Indian languages and wanted to know the procedure to prepare the dateset for English to Hindi content and train the model for the same. Can you help me on this as I’m facing challenge in Data preparation itself.
Error
Traceback (most recent call last):
File “/usr/lib/python3.6/multiprocessing/pool.py”, line 119, in worker
result = (True, func(*args, **kwds))
File “/home/optimus9_app/.local/lib/python3.6/site-packages/onmt/bin/preprocess.py”, line 54, in process_one_shard
assert len(src_shard) == len(tgt_shard)
AssertionError
“”"
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File “/home/optimus9_app/.local/bin/onmt_preprocess”, line 8, in
sys.exit(main())
File “/home/optimus9_app/.local/lib/python3.6/site-packages/onmt/bin/preprocess.py”, line 318, in main
preprocess(opt)
File “/home/optimus9_app/.local/lib/python3.6/site-packages/onmt/bin/preprocess.py”, line 298, in preprocess
‘train’, fields, src_reader, tgt_reader, align_reader, opt)
File “/home/optimus9_app/.local/lib/python3.6/site-packages/onmt/bin/preprocess.py”, line 205, in build_save_dataset
for sub_counter in p.imap(func, shard_iter):
File “/usr/lib/python3.6/multiprocessing/pool.py”, line 735, in next
raise value
AssertionError
Dear Ankit,
Could you please paste the contents of your preprocessing *.yml file here to see if it is correct.
My preprocessing file looks like this:
## Where the samples will be written
save_data: run/enhi
## Where the vocab(s) will be written
src_vocab: run/enhi.vocab.src
tgt_vocab: run/enhi.vocab.tgt
# Prevent overwriting existing files in the folder
overwrite: False
# Corpus opts:
data:
corpus_1:
path_src: all.tokenized.subword.train.en
path_tgt: all.tokenized.subword.train.hi
valid:
path_src: all.tokenized.subword.dev.en
path_tgt: all.tokenized.subword.dev.hi
I suggest that you follow the Quick Start tutorial first to make sure you understand how OpenNMT-py works, and only after this try to apply it of your own data.
Kind regards,
Yasmin
1 Like
Corpus opts:
data:
corpus_1:
path_src: data/src-train.txt
path_tgt: data/tgt-train.txt
valid:
path_src: data/src-val.txt
path_tgt: data/tgt-val.txt
Dear Ankit,
File “/home/optimus9_app/.local/lib/python3.6/site-packages/onmt/bin/preprocess.py”, line 54, in process_one_shard
assert len(src_shard) == len(tgt_shard)
AssertionError
Revising your error message again, it seems to me that you are using an old version of OpenNMT-py. Please make sure you download and install the latest version.
git clone https://github.com/OpenNMT/OpenNMT-py.git
cd OpenNMT-py
If you are using a virtual environment, please activate it before the following step:
python3 setup.py install
While the error above is from an older version, it suggests that there might be an issue in your data files, like the number of lines in the source is not the same as the target.
Anyhow, after installing the latest version, I recommend you apply the Quick Start first. It will take half an hour maybe, but you will be sure you got the right process. Feel free to follow up here.
Kind regards,
Yasmin
Dataset I’m using for training
src-- src-valeng.txt
Hallmarking is Europe " s earliest form of consumer protection and probably started in France , the standard for silver being established in 1260 .
Apparently the Commission is discussing a paper with the Member States without even informing Parliament that it is doing so .
Mr President , Commissioner Fischler , rural development can and must tackle the problem from three different angles: preservation of jobs , stewardship of the countryside and , not least , local culture , because that is of the utmost importance .
I think that the EU should be prepared to face any attack or accident which jeopardises Europeans ’ security and health .
tgt --tgt-valhi.txt
हॉलमार्किंग यूरोप में उपभोक्ता संरक्षण का सबसे पहला रूप है और संभवतः फ्रांस में शुरू हुआ, 1260 में स्थापित होने वाला चांदी का मानक।
जाहिर तौर पर आयोग संसद को सूचित किए बिना भी सदस्य देशों के साथ एक पेपर पर चर्चा कर रहा है कि वह ऐसा कर रहा है।
श्री अध्यक्ष, आयुक्त फिशरेल, ग्रामीण विकास तीन अलग-अलग कोणों से समस्या का सामना कर सकते हैं और होना चाहिए: नौकरियों का संरक्षण, ग्रामीण इलाकों का वध और कम से कम, स्थानीय संस्कृति, क्योंकि यह अत्यंत महत्व का है।
मुझे लगता है कि यूरोपीय संघ को किसी भी हमले या दुर्घटना का सामना करने के लिए तैयार रहना चाहिए जो यूरोपीय लोगों को परेशान करता है; सुरक्षा और स्वास्थ्य।
Wanted to know how to create how to do so
vocab-train.src
vocab-train.tgt
Dear Ankit,
The data looks okay if these are a few lines of it. You need enough data to be able to build a machine translation model. You can find data at:
Have you managed to run the Quick Start?
Kind regards,
Yasmin
Dear Yasmin,
I’m trying to run the Quick start but getting this error
onmt_train -config toy_en_de.yaml
Traceback (most recent call last):
File “/home/optimus9_app/.local/bin/onmt_train”, line 5, in
from onmt.bin.train import main
File “/home/optimus9_app/.local/lib/python3.6/site-packages/onmt/bin/train.py”, line 12, in
from onmt.train_single import main as single_main
File “/home/optimus9_app/.local/lib/python3.6/site-packages/onmt/train_single.py”, line 7, in
from onmt.inputters.inputter import build_dataset_iter, patch_fields,
ImportError: cannot import name ‘patch_fields’
And I have large dataset its was just a sample that I shared
What version are you using? This looks like you might have several versions conflicting, strange.
Dear Ankit,
As François said, to avoid all of this, you might try to install a virtual environment and install OpenNMT-py inside it.
- Install
virtualenvif you do not have it already:
sudo pip3 install virtualenv
- Create a virtual environment:
mkdir .venvs
cd .venvs
virtualenv -p /usr/bin/python3 onmtpy
- Activate the virtual environment
source onmtpy/bin/activate
- Get out of the virtual environment:
cd
- Download and install OpenNMT-py:
git clone https://github.com/OpenNMT/OpenNMT-py.git
cd OpenNMT-py
python3 setup.py install
Every time, you want to use this version of OpenNMT-py (after restarting your machine), you have to activate the associated virtual environment as in step #3.
source ~/.venvs/onmtpy/bin/activate
I hope this helps.
Kind regards,
Yasmin
Thanks François & Yasmin for your help.
I was able to create the virtual environment and its working fine
I fallowed the steps in quick start
pip install OpenNMT-py
wget https://s3.amazonaws.com/opennmt-trainingdata/toy-ende.tar.gz
tar xf toy-ende.tar.gz
cd toy-ende
my config
# toy_en_de.yaml
Where the samples will be written
save_data: run/ende
Where the vocab(s) will be written
src_vocab: run/ende.vocab.src
tgt_vocab: run/ende.vocab.tgt
Prevent overwriting existing files in the folder
overwrite: False
Corpus opts:
data:
corpus_1:
path_src: toy-ende/src-train.txt
path_tgt: toy-ende/tgt-train.txt
valid:
path_src: toy-ende/src-val.txt
path_tgt: toy-ende/tgt-val.txt
but while running this configuration, we can build the vocab(s), that will be necessary to train the model:
I’m getting this error while running this command
onmt_build_vocab -config toy_en_de.yaml -n_sample 10000
Traceback (most recent call last):
File “/home/optimus9_app/.venvs/onmtpy/bin/onmt_build_vocab”, line 33, in
sys.exit(load_entry_point(‘OpenNMT-py==2.0.0rc2’, ‘console_scripts’, ‘onmt_build_vocab’)())
File “/home/optimus9_app/.venvs/onmtpy/bin/onmt_build_vocab”, line 25, in importlib_load_entry_point
return next(matches).load()
StopIteration
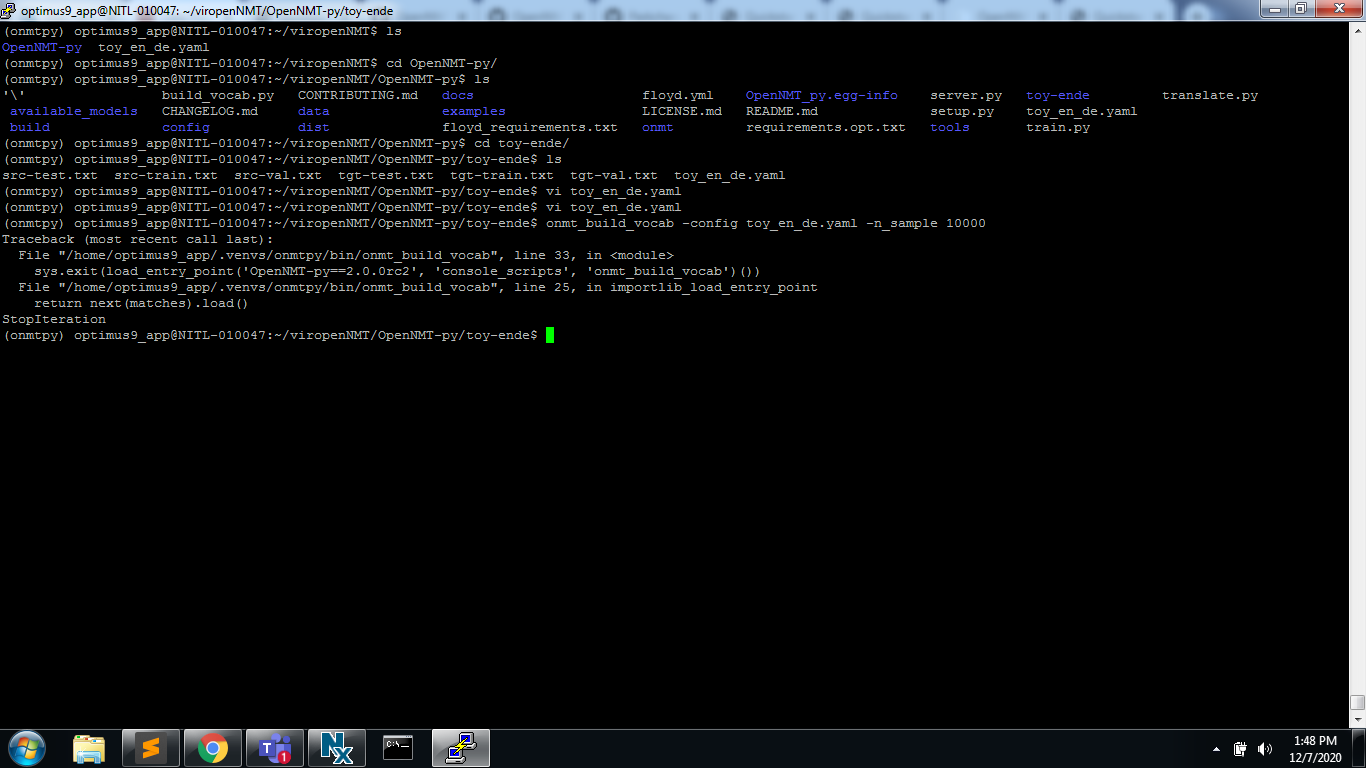
Please help me on this
Is OpenNMT installed on Windows or Linux?
i’m using Linux it’s a GPU server
Dear Ankit,
It seems you have installed OpenNMT-py twice: once with setup.py and once using pip, which installs two different versions. Do NOT do this!
When I tried to install the latest version of OpenNMT-py, I got the message: RuntimeError: Python version >= 3.7 required.
I followed this tutorial to install Python 3.7 (and still keep Python 3.6).
You can also do the same. After this, delete the old onmtpy virtual environment and create a new one, activate it, and make sure the version of Python in it is 3.7.
Now, try again downloading and installing OpenNMT-py.
git clone https://github.com/OpenNMT/OpenNMT-py.git
cd OpenNMT-py
python3 setup.py install
Please do NOT use pip after this. Directly run the toy task.
onmt_build_vocab -config toy_en_de.yaml -n_sample 10000
I hope this helps.
Kind regards,
Yasmin
Hi Yasmin,
Thanks for your help now I’m able to run the Quickstart.
As I have told you that wanted to convert from English to Hindi i have prepared the dataset for the same but I’m facing problem in creating and understanding
example.vocab.src example.vocab.tgt these two files.
Please help me to created these.
how scores are given?
Hi Ankit,
Great that you now managed to install OpenNMT and run the quick start tutorial.
I am not sure I understand your question. What do you mean by “convert”? If you mean “translate”, have you followed the 3 steps of the quick start tutorial? What are you stuck at exactly? vocab.src and vocab.tgt are the files created from the building vocabulary step, after which you need to move to the training step, and then the translation step.
I am CCing @francoishernandez in the case he can help further.
Kind regards,
Yasmin
Thanks Yasmin & François for your help.
I have completed the training for English to Hindi Content and getting results for the same.
@ymoslem
I used to train using Opennmt-py (last version 0.9.2), I see lots of updates have been made since then.
I have couple of doubts and confusion
My previous pipeline used to be like this:
Apply BPE using sentencepiece models trained outside of opennmt, on the source language and target language
Run python preprocess.py
python preprocess.py -train_src data/src-train.txt -train_tgt data/tgt-train.txt -valid_src data/src-val.txt -valid_tgt data/tgt-val.txt -save_data data/procData_2019
Run train.py
python train.py -data data/procData_2019 -save_model model/model_2019-model -layers 6 -rnn_size 512 -word_vec_size 512 -transformer_ff 2048 -heads 8 -encoder_type transformer -decoder_type transformer -position_encoding -train_steps 100000 -max_generator_batches 2 -dropout 0.1 -batch_size 4096 -batch_type tokens -normalization tokens -accum_count 2 -optim adam -adam_beta2 0.998 -decay_method noam -warmup_steps 8000 -learning_rate 0.25 -max_grad_norm 0 -param_init 0 -param_init_glorot -label_smoothing 0.1 -valid_steps 10000 -save_checkpoint_steps 10000 -world_size 1 -gpu_ranks 0
I can see now there is no preprocess.py (build_vocab.py, is it the same ?) what is -n_sample 10000
I used to train sentencepiece bpe model externally with vocab_size = 24000
Can anyone tell how exactly to achieve above in new OpenNMT-py release.?