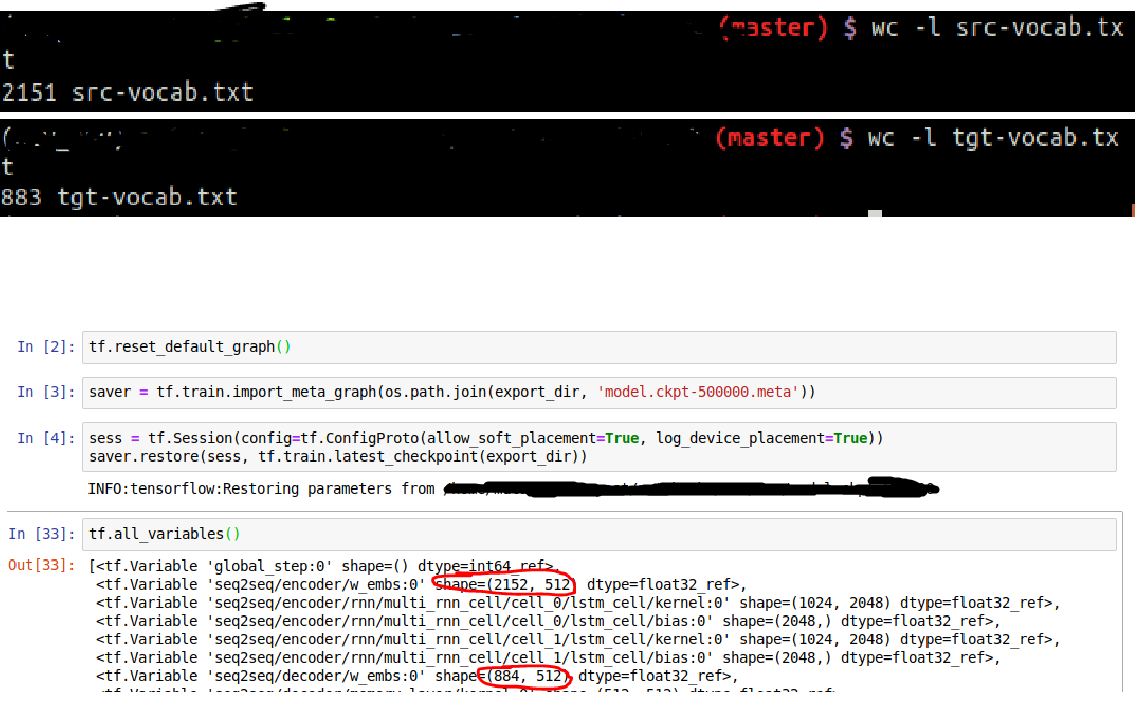
Hello, I have some doubts about the generated word embedding for NMTSmall architecture. As far as I know about word embeddings and neural architectures, word embedding matrix is supposed to be in vocab_source_sizeXembedding_size space. It happens quite the same with target words embeddings. However, when I was playing around with the generated embeddings, I found out that the dimensions does not corresponds to the source/target vocabulary. You can see the picture below…
I thought about the special tokens (, and so on), but vocabulary files contains special tokens too, so I can’t find out why the embedding matrix is in (vocab_size+2)Xsize_embedding space. If you can explain to me the reason, I will appreciate it.
Thank you a lot for the quickly response. However, since the index begin in 0, it supposed to be [(vocab_size-1) + 1, embedding_size]. Vocab_size-1 is because of indexation and the +1 because of the OOV token. In my case it is still one more dimension.