Hi There,
I’m using the OpenNMT-tf repo for building the English-Arabic model. Previously, I have used the same for building English-Spanish model which has given pretty decent results like BLEU scores in the mid 60’s. I had used the following steps for English - Spanish:
Tokenize(OpenNMT Tokenizer) - BPE - Learn Alignments - Learn Model with Alignments
This has worked well for Domain Adaption (DA) as well. Now, when I run the same steps for English to Arabic with the default OpenNMT tokenization I get okayish scores like ~25 BLEU (not bad when compared to research paper results I have seen). Lot of the topics here suggest to try Sentence Piece tokenization for Arabic language which has seem to work in the past. In short, when I try running sentence piece on the my dataset for some weird reason predictions turn out to be in English however I want them to be in Arabic.
Below are the steps I have run-
-
Downloaded the spm library from Google Sentence Piece
-
Combine the train dataset into one file to learn joint sentence piece model
cat train_large_en.txt train_large_ar.txt > /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/sp/sp_input_combine_file.txt -
Train the model on Combined english-arabic dataset (its a combination of subsets from QCIR Domain Corpus, UN parallel data, Arab Acquis data, OpenSubtitles ; in total about 2M sentences)
spm_train --input=/home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/sp/sp_input_combine_file.txt --model_prefix=spm --vocab_size=32000 --character_coverage=0.9995 -
Generate the English and Arabic vocabulary files
spm_encode --model= /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/spm.model --generate_vocabulary < train_large_en.txt > /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/sp_vocab/vocab.enspm_encode --model=/home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/sp/spm.model --generate_vocabulary < train_large_ar.txt > /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/sp_vocab/vocab.ar -
Encode the train,dev,test files (english and arabic) with the learnt spm model
spm_encode --model=/home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/sp/spm.model --vocabulary=/home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/sp_vocab/vocab.en < /home/ubuntu/mayub/datasets/raw/arabic/large_v2/test_large_en.txt > /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/test_sp_applied.en -
(Optional Generating the alignments file)
-
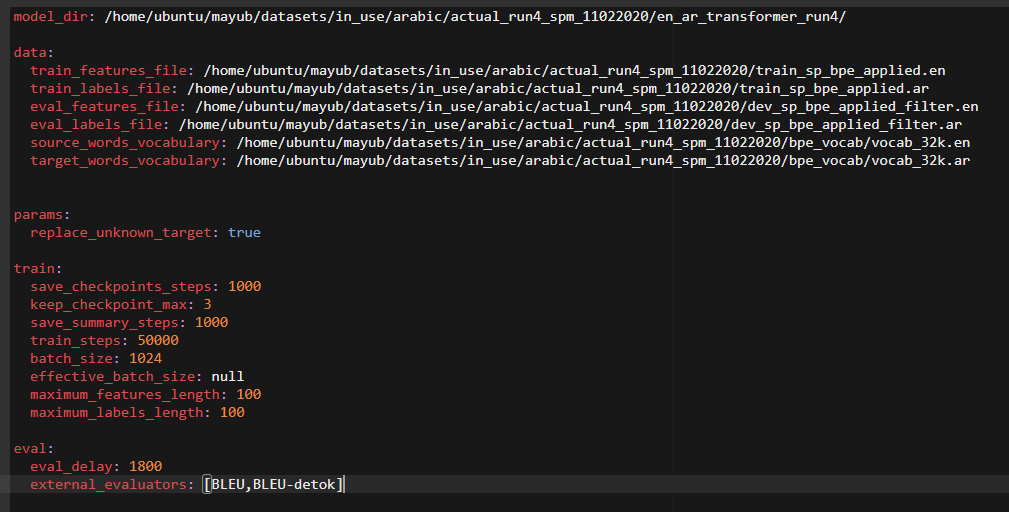
Pass above spm encoded files to OpenNMT-tf for Training the NMT model. Config file is as below:
model_dir: /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/en_ar_transformer_b/
data:
train_features_file: /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/train_sp_applied.en
train_labels_file: /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/train_sp_applied.ar
eval_features_file: /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/dev_sp_applied.en
eval_labels_file: /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/dev_sp_applied.en
source_words_vocabulary: /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/sp/spm_clean_src.txt
target_words_vocabulary: /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/sp/spm_clean_trg.txt
params:
guided_alignment_type: ce
guided_alignment_weight: 1
replace_unknown_target: true
train:
save_checkpoints_steps: 1000
keep_checkpoint_max: 3
save_summary_steps: 1000
train_steps: 25000
batch_size: 1024
effective_batch_size: null
maximum_features_length: 100
maximum_labels_length: 100
eval:
eval_delay: 1800
external_evaluators: [BLEU,BLEU-detok]
- train command:
onmt-main train_and_eval --model_type Transformer --config /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/actual_run_3_sp.yml --auto_config --num_gpus 1 2>&1 | tee /home/ubuntu/mayub/datasets/in_use/arabic/actual_run3_sp/en_ar_transformer_large_sp.log
Sample Predictions File -

All files that I’m using are in available here for reference. I’m not sure if I’m missing something which I should be doing. Please advice.
Thanks !
Mohammed Ayub