When training a model with a large vocabulary (e.g. 100k words), the bottleneck for the training speed is the estimation of the softmax layer. This has been extensively described in literature and @vince62s was requesting for quite some time that we experiment on alternative approaches for the generation layer. As a reminder time spent in each module can be profiled using OpenNMT with -profiler option.
Jean et al. in On Using Very Large Target Vocabulary for Neural Machine Translation propose use of importance sampling and show that it accelerates significantly training and reach close to state of the art performance.
The following page describes also very well the problematic and the different approaches for speeding up or replacing softmax layer:
We report here some preliminary results with OpenNMT using Noise Contrastive Estimation module as implemented in the excellent torch dpnn library.
For the experiment, the training corpus is OpenNMT enfr baseline 1M corpus, tokenized with -joiner_annotate and we keep a vocabulary size of 100k (source and target). We report the training perplexity for a sequence of configurations with default OpenNMT parameters (simple rnn, 2 layers, 500 rnn_size, 500 word_vec_size, 13 epochs, SGD, start decay at 9 epochs):
-
full: the full softmax training -
nceN*13: 13 epochs of NCE training with sample sizeN -
nceN*n-fullorfull*n-nceN: mix of NCE for the firstnepochs then switch to full softmax (or the reverse)
The following graph show the (time,perplexity) graph. Each marker is corresponding to one epoch. Dotted lines show when a change of generator happens. Several training have been made for all configurations, but we only show an average one. Perplexity calculation is done using full softmax so can be compared between NCE and full softmax configurations.
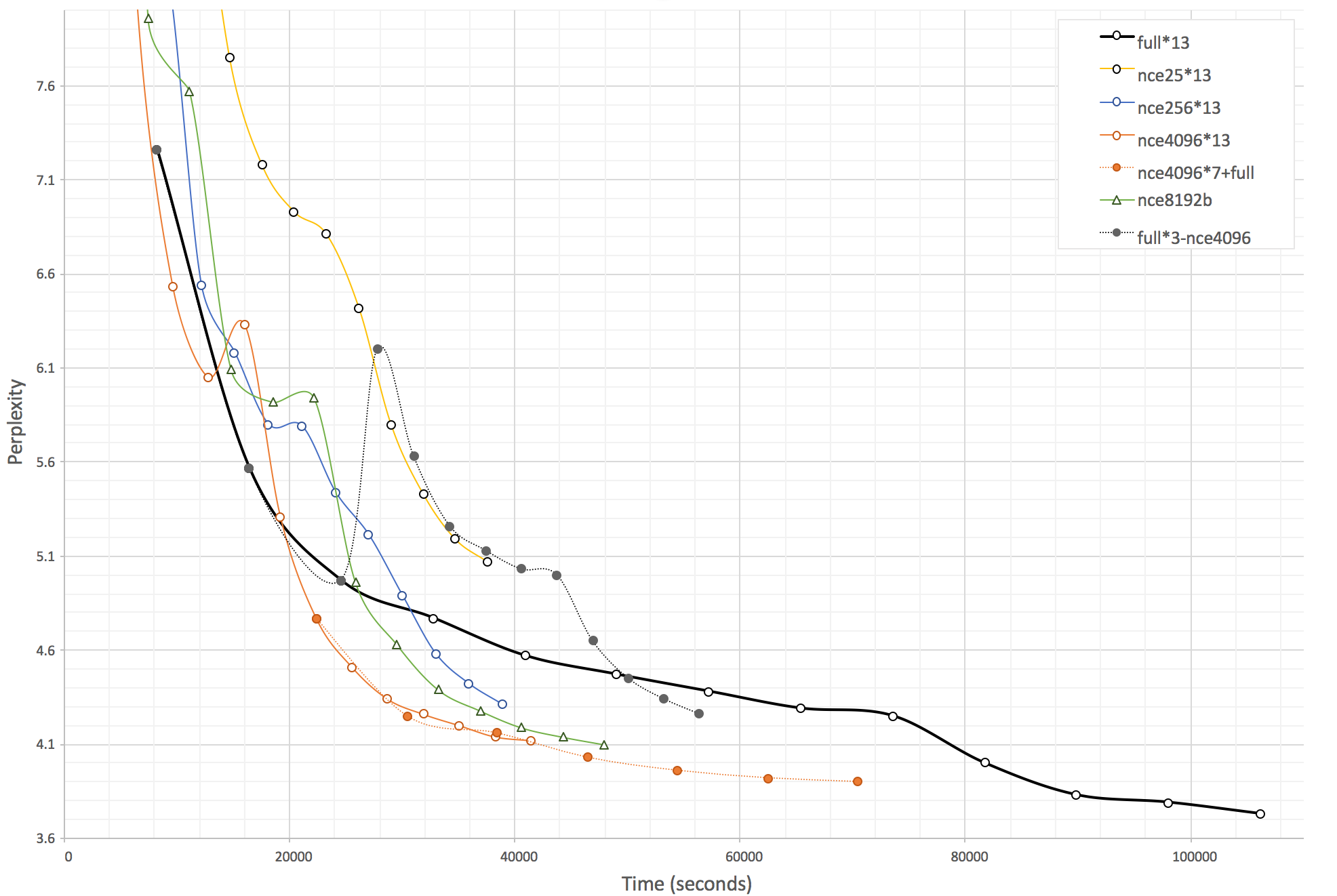
In short the conclusions are:
- Speed of NCE based training does not really depend on the sample size (at least with sample size between 25 and 4096) - and use of NCE more than double the speed of the training
- NCE 4096-8192 arrive to about the same PPL at the end of the training
- Even if PPL reaches ~4 for best performing NCE configuration at about half of the time need for full softmax, no NCE based configuration manages to get final perplexity as low as full softmax final perplexity in 13 epochs (more epochs might reach the point)
- Starting with NCE for the first half of the training then switching to full softmax is not very far to the full softmax
- Doing the reverse is giving very bad results due to a huge PPL raise at the first step of the transition
Feel free to share your thoughts on this topic!