How do use OpenNMT incremental learning, or combine the two models for translation.
incremental trainong could be achieved through the -continue option I guess.
Here is a conversation on gitter:
vince62s
@vince62s
18:22
Guys, reading this from the doc: “If training from a checkpoint, whether to continue the training in the same configuration or not.” How different can the configuration be in continue mode ?
not the place, sorry
Guillaume Klein
@guillaumekln
18:26
You use -continue when you stopped a training a want to resume it on the last checkpoint. Without -continue it is a new training using the parameters of the checkpoint.
vince62s
@vince62s
18:47
my was more about: I presume you need to keep the shape of the rnn but can we for instance change the dropout ratio for a “resumed” training ?
srush
@srush
18:47
You might for instance, want to change the learning rate or the printing criterion
vince62s
@vince62s
18:47
ok gotcha.
srush
@srush
18:47
you currently can’t change the topology of the model at all no
it’s not clear how your would map the old parameters to new for instance
changing dropout is currently not supported, if there was a use case that could be done in theory
(mind posting to forum though with answers? think other people will have this issue)
Thanks for sharing this.
I think you said how to resume a uncompleted training from a checkpoint, right? It maybe not the incremental training condition. If I have two batches of Corpus (B1 and B2), I completed the training for B1, and after some time, I got another batch of Corpus - B2, how can I let the trained engine from B1 to learn the B2 corpus?
If we trained another engine for B2, and try to merge B1 engine and B2 engine, it seems impossible from below article:
Please correct me if wrong.
Hi again,
I try to make incremental training from a ready model - en-US_zh-CN_epoch13_2.15.t7.
For the new Corpus, I have ran tokenize.lua, preprocess.lua and get , en_zh.src.dict, en_zh.tgt.dict, en_zh-train.t7.
I ran below commands to launch the incremental training:
th train.lua -data /home/en_zh-train.t7 -save_model /home/en_zh -train_from /home/en-US_zh-CN_epoch13_2.15.t7 -continue
Below errors appear:
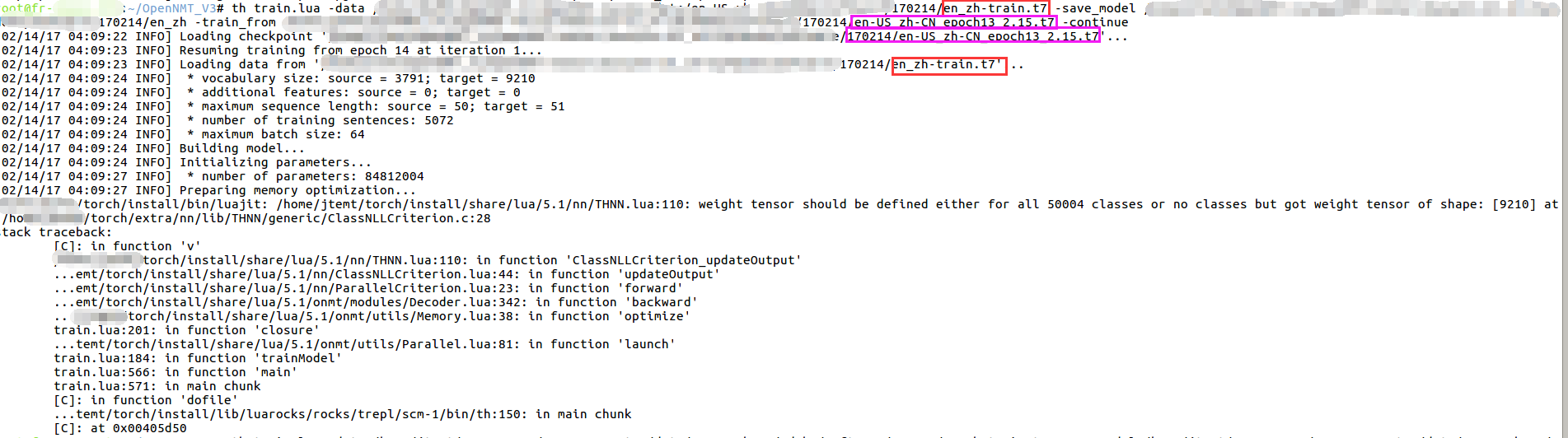
Would you please advise if anything wrong I made?
Thanks very much.
Please ignore my previous comments, I found the solution on another article on GitHub.
https://github.com/OpenNMT/OpenNMT/issues/72
Hope this is helpful for others.