This tutorial describes how to perform End-to-End English speech recognition using Pyramidal Deep Bidirectional Encoder in OpenNMT
1. Data preparation
OpenNMT requires source and target for training. For the speech recognition, source is a sequence of acoustic feature and target is a sequence of characters (i.e. transcription). Here we make use of Wall Street Journal (WSJ) speech corpus where about 70 hours of 16KHz English speech are available. The following Github repository helps to build training, dev, and test set of source and target from from the WSJ corpus using a Kaldi speech recognition toolkit.
2. Lua 5.2 installation
A sequence of acoustic feature is quite heavy to be running completely. Lua 5.2 helps to load such large data in OpenNMT. LuaJIT user will need to limit the length of source and target sequences. You can install Lua 5.2 as shown in the following.
git clone https://github.com/torch/distro.git ~/torch --recursive
cd torch
TORCH_LUA_VERSION=LUA52 ./install.sh
3. Training
th preprocess.lua -data_type 'feattext' \
-train_src wsj_train_fbank_fbank120.txt \
-train_tgt wsj_train_fbank_trans_nm.txt \
-valid_src wsj_dev_fbank_fbank120.txt \
-valid_tgt wsj_dev_fbank_trans_nm.txt \
-save_data wsj_kaldi_nm_fb120 \
-idx_files -src_seq_length 2450 -tgt_seq_length 330
NAME=asr_wsj_pdbrnn_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm
CUDA_VISIBLE_DEVICES=0 \
~/torch/install/bin/th train.lua \
-data wsj_kaldi_nm_fb120-train.t7 \
-save_model $NAME -encoder_type pdbrnn -report_every 1 \
-rnn_size 256 -word_vec_size 50 -enc_layers 3 -dec_layers 3 -max_batch_size 6 \
-learning_rate 0.2 -dropout_type naive -dropout 0 \
-learning_rate_decay 1 -start_decay_at 10 -end_epoch 30 -pdbrnn_merge concat \
-residual false -gpuid 1
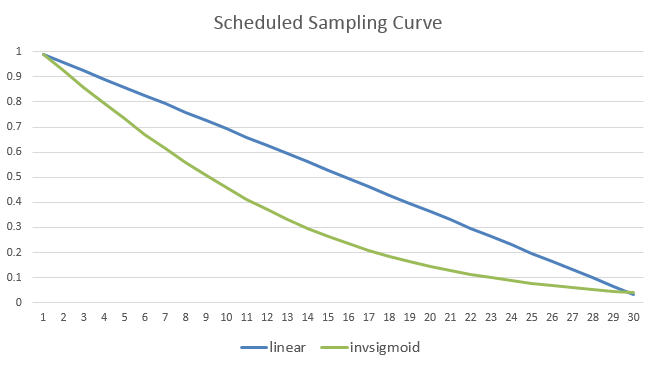
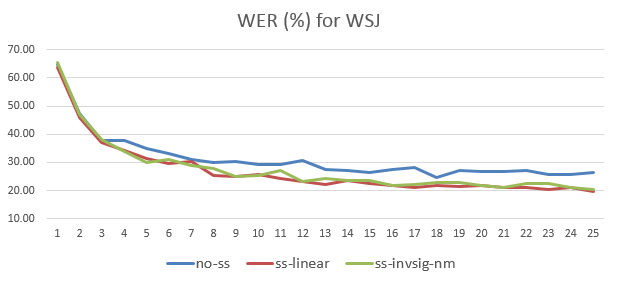
OpenNMT supports training feature called Scheduled Sampling, which can be configured in the following. You can set parameter values depending upon your preference. Here, I set inverse sigmoid up to epoch 30.
NAME=asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm
CUDA_VISIBLE_DEVICES=0 \
~/torch/install/bin/th train.lua \
-data wsj_kaldi_nm_fb120-train.t7 \
-save_model $NAME -encoder_type pdbrnn -report_every 1 \
-rnn_size 256 -word_vec_size 50 -enc_layers 3 -dec_layers 3 -max_batch_size 6 \
-learning_rate 0.2 -dropout_type naive -dropout 0 \
-learning_rate_decay 1 -start_decay_at 10 -end_epoch 25 -pdbrnn_merge concat \
-scheduled_sampling 0.99 -scheduled_sampling_decay_rate 7.5 \
-scheduled_sampling_scope token -scheduled_sampling_decay_type invsigmoid \
-residual false -gpuid 1
4. Prediction
NAME=asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm
src_file=wsj_test_fbank_fbank120.txt
tgt_file=wsj_test_fbank_trans_nm.txt;
wer_file=$RESULT/WER_$NAME.txt
gold_file=$(mktemp /tmp/gold.XXXXXX);pred_file=$(mktemp /tmp/pred.XXXXXX)
[ -e $wer_file ] && rm -f $wer_file
for ((epoch_cn=1;epoch_cn<=25;epoch_cn++))
do
model=$(ls $NAME"_"epoch$epoch_cn"_"*)
output=$NAME"_"epoch$epoch_cn.out
full_output=$NAME"_"epoch$epoch_cn.out.log
echo $model >> $wer_file
CUDA_VISIBLE_DEVICES=0 \
~/torch/install/bin/th translate.lua \
-src $src_file -tgt $tgt_file -model $model \
-output $output -batch_size 1 -gpuid 1 -idx_files true > $full_output
grep GOLD $full_output | grep -v SCORE | perl -pe 's/.*: //g;s/ //g;s/_/ /g' > $gold_file
grep PRED $full_output | grep -v SCORE | perl -pe 's/.*: //g;s/ //g;s/_/ /g' > $pred_file
python wer++.py $pred_file $gold_file >> $wer_file
done
WER is obtained using wer++.py. As epoch increases, the prediction of 11th speech utterance below is improved.
>> grep -w "GOLD 11" *_nm_epoch1.out.log
[09/15/17 22:51:48 INFO] GOLD 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
>> grep -w "PRED 11" *_nm_epoch*
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch1.out.log:
[09/15/17 22:51:48 INFO] PRED 11: t h e _ w a r l i n g _ t r e n d _ m a y _ h a v e _ m o t e d _ t h e _ s k i l l _ c o v e r o n _ s o m e _ c r o b e s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch2.out.log:
[09/15/17 23:04:01 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch3.out.log:
[09/15/17 23:15:28 INFO] PRED 11: t h e _ w o r m i n g _ t r e n d _ m a y _ h a v e _ m o t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch4.out.log:
[09/15/17 23:26:56 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch5.out.log:
[09/16/17 22:23:14 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch6.out.log:
[09/16/17 22:34:29 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m o t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch7.out.log:
[09/16/17 22:45:56 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch8.out.log:
[09/16/17 22:57:26 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l i t i d _ t h e _ s n o c k o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch9.out.log:
[09/17/17 21:42:58 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e a l t e d _ t h e _ s n o w _ c o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch10.out.log:
[09/17/17 21:54:22 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s k n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch11.out.log:
[09/17/17 22:05:50 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h i s _ n o _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch12.out.log:
[09/17/17 22:17:08 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h i s _ n o _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch13.out.log:
[09/18/17 11:20:39 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch14.out.log:
[09/18/17 11:31:49 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch15.out.log:
[09/19/17 10:04:05 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch16.out.log:
[09/19/17 10:15:24 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch17.out.log:
[09/19/17 10:27:02 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch18.out.log:
[09/19/17 10:38:35 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch19.out.log:
[09/19/17 15:05:39 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l v e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch20.out.log:
[09/19/17 22:57:40 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l v e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch21.out.log:
[09/25/17 11:03:35 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch22.out.log:
[09/25/17 11:15:53 INFO] PRED 11: t h e _ w o r m i n g _ t r e n d _ m a y _ h a v e _ m e l v e d _ t h i s _ n o _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch23.out.log:
[09/25/17 11:31:32 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch24.out.log:
[09/25/17 11:43:13 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e a l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm_epoch25.out.log:
[09/25/17 11:54:25 INFO] PRED 11: t h e _ w a r m i n g _ t r e n d _ m a y _ h a v e _ m e l t e d _ t h e _ s n o w _ c o v e r _ o n _ s o m e _ c r o p s
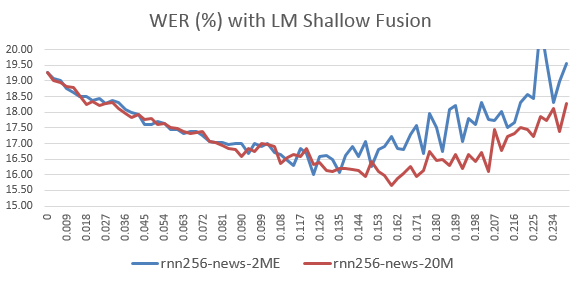
5. LM Shallow Fusion
OpenNMT supports decoding feature called the LM Shallow Fusion which improves further. LM needs to be trained first with the dictionary produced from the data preparation above and it can be configured as follows. Here we made use of in-house English corpus 2M and 20M TUs.
5.1 LM training
~/torch/install/bin/th preprocess.lua \
-data_type monotext \
-train /CI_news-uniq.en.tok \
-seq_length 700 \
-valid CI_news-dev.en.tok \
-save_data CI_news-uniq.en.tok \
-vocab wsj_kaldi_fb120.tgt.dict
CUDA_VISIBLE_DEVICES=0 \
~/torch/install/bin/th train.lua \
-data CI_news-uniq.en.tok-train.t7 \
-save_model CI_news-uniq.en.tok_lm_r1024_wv500_l2 \
-model_type lm -report_every 1 -max_batch_size 300 -end_epoch 35 \
-rnn_size 1024 -word_vec_size 500 -layers 2 \
-learning_rate 0.1 -learning_rate_decay 1.0 \
-gpuid 1
5.2 Decoding with the Shallow Fusion
NAME=asr_wsj_pdbrnn_0.99_7.5_token_invsigmoid_fb120_pdbrnn_E3_D3_rnn256_sgd0.2_naive0_nm
src_file=wsj_test_fbank_fbank120.txt
tgt_file=wsj_test_fbank_trans_nm.txt;
wer_file=WER_$NAME.txt
gold_file=$(mktemp /tmp/gold.XXXXXX);pred_file=$(mktemp /tmp/pred.XXXXXX)
[ -e $wer_file ] && rm -f $wer_file
for epoch_cn in 25
do
model=$(ls $NAME"_"epoch$epoch_cn"_"*)
lw=0.000;incl=0.003
for iter in {1..80..1}
do
lw=`echo $lw + $incl | bc`
output=$NAME"_"epoch$epoch_cn.out
full_output=$NAME"_"epoch$epoch_cn.out.log
echo $model"_"$lw >> $wer_file
CUDA_VISIBLE_DEVICES=0 \
~/torch/install/bin/th translate.lua \
-src $src_file -tgt $tgt_file -model $model \
-lm_model CI_news-uniq.en.tok_lm_r1024_wv500_l2_epoch31_2.26.t7 \
-lm_weight $lw -output $output -batch_size 1 -gpuid 1 -idx_files true > $full_output
grep GOLD $full_output | grep -v SCORE | perl -pe 's/.*: //g;s/ //g;s/_/ /g' > $gold_file
grep PRED $full_output | grep -v SCORE | perl -pe 's/.*: //g;s/ //g;s/_/ /g' > $pred_file
python wer++.py $pred_file $gold_file >> $wer_file
done
done